We help companies build & improve their AI products with our hands-own
services. Request a consultation
here.
Check out the discussion on Hacker
News. Thanks for all the
feedback and comments!
claude-3-opus-20240229), the cheapest one (claude-3-haiku-20240307) with OpenAI’s GPT-4 Turbo model (gpt-4-0125-preview) and GPT-3.5 Turbo model (gpt-3.5-turbo-0125).
A huge thanks to the team at Berkeley for preparing this dataset and making it available to the public.
You can find the code to reproduce the results here and experiment details are publicly available here.
The full results (with graph) are in the Results section.
Note, we will use function and tool interchangeably in this post.
Berkeley Function Calling Leaderboard (BFCL) Dataset
We chose the Abstract Syntax Tree (AST) Evaluation subset of the BFCL dataset which compromises 1000 out of the total 1700 samples. It contains the following categories (from here): Simple Function: These 400 samples are the simplest but most commonly seen format, where the user gives a single JSON function/tool definition, with one and only one function call will be invoked. Multiple Function: These 200 samples consist of a user question that only invokes one function call out of 2 to 4 JSON tool definitions. The model needs to be capable of selecting the best function to invoke according to user-provided context. Parallel Function: These 200 samples are defined as invoking multiple function calls in parallel with one user query. The model needs to digest how many function calls need to be made and the question to model can be a single sentence or multiple sentence. Parallel Multiple Function: Each of these 200 samples is the combination of parallel function and multiple function. In other words, the model is provided with multiple tool definition, and each of the corresponding tool calls will be invoked zero or more times.Abstract Syntax Tree (AST) Evaluation
The full details on how the evaluation process works can be found here. The main idea is to compare the abstract syntax tree (AST) of the function call generated by the model with the AST of the correct answer. Here are the relevant parts: To evaluate the simple & multiple function category, the evaluation process compares the generated function call against the given function definition and possible answers. Then, it extracts the arguments from the AST and checks if each required parameter can be found and exact matched in the possible answers with the same type. The parallel, or parallel-multiple function AST evaluation process extends the idea of the above evaluation to support multiple model outputs and possible answers. It applies the simple function evaluation on each generated function call and checks if all the function calls are correct. Note, this evaluation is invariant under the order of the function calls.Results
For simple & multiple tool use, we can see that Haiku beats all the other models! However, both Haiku and Opus struggle to generate multiple function calls in parallel, i.e., with a single API call. It’s also interesting to observe how GPT-3.5 Turbo is much closer in performance to GPT-4 Turbo when generated function calls in parallel vs. when not. Below is a graph of the results which compares the accuracy of the 4 models to generate the correct function call(s) under different conditions.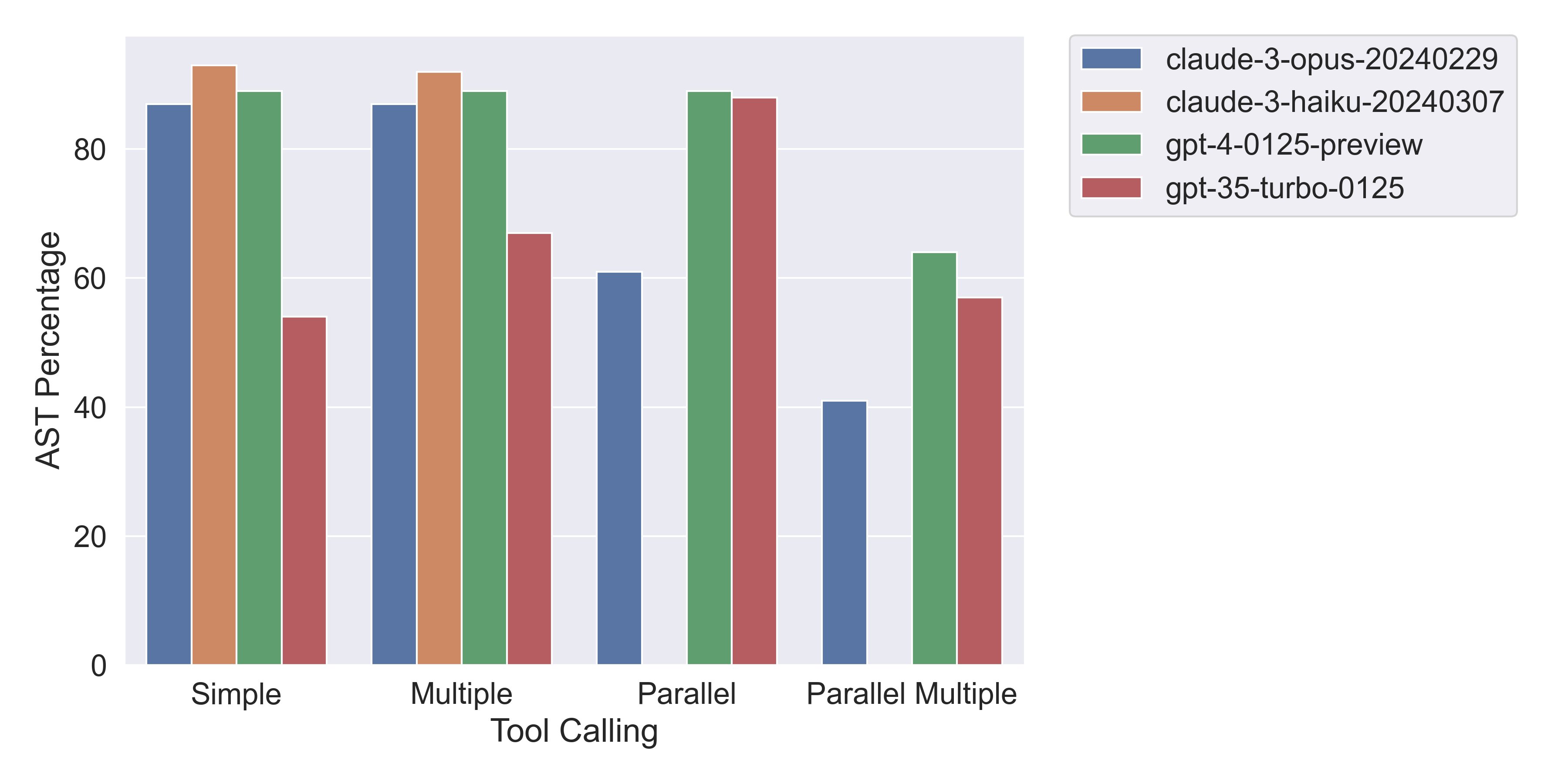
Overview of major error types for each tool use & model scenario
Overview of major error types for each tool use & model scenario
The table below shows for every tool use scenario and model, the error rate, the number of errors, the major error type, and the number of major errors.
You can see a definition of the error types below the table.
Explanation of error types:
Invalid value for parameter: generated value for parameter was incorrectWrong number of functions: generated too many or too few function callsCould not find a matching function: one or more function calls were incorrect