We help companies build & improve their AI products with our hands-own services. Request a consultation here.
1. Hypothesis Testing with Prompt Engineering
Start simple. Begin with one of the leading foundation models and test your hypothesis using basic prompt engineering. The goal here isn’t perfection but establishing a baseline and confirming that the LLM can produce reasonable responses for your use case. If you already have a prompt/chain in place, skip to the next step. Don’t spend too much time engineering your prompt at this stage. After you collect more data, you can make hypothesis-driven tweaks.2. Dataset Creation from Users
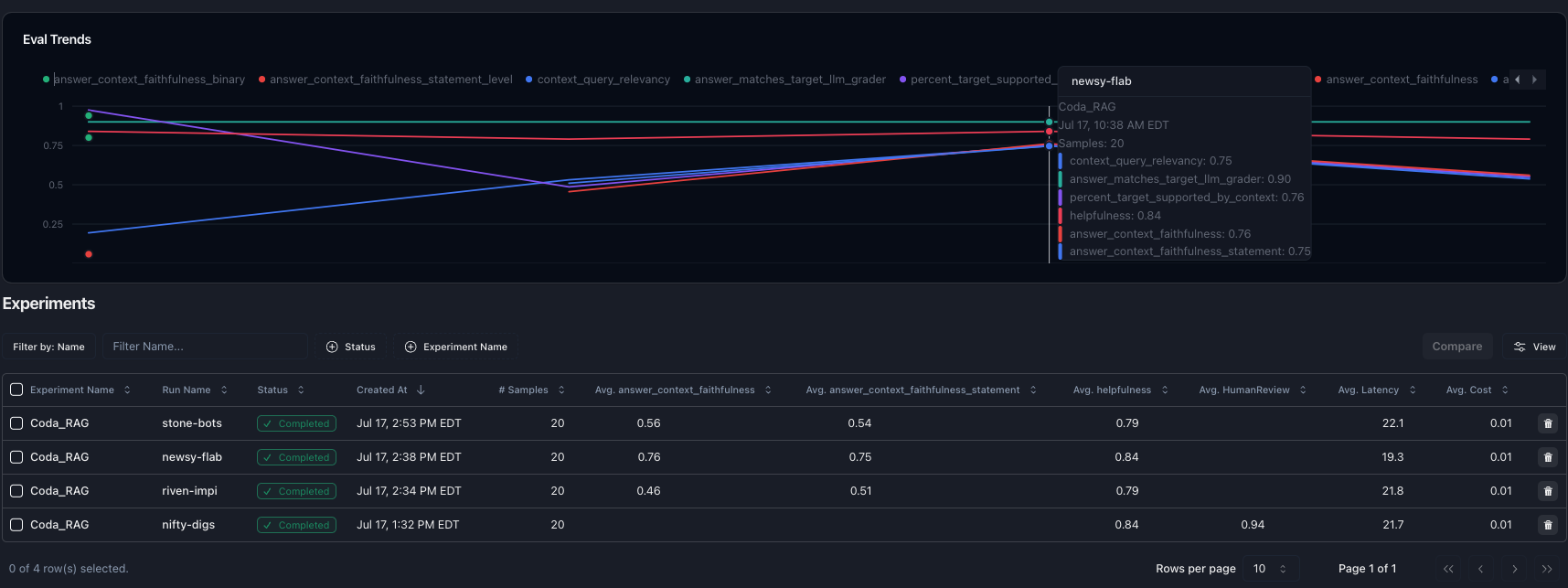
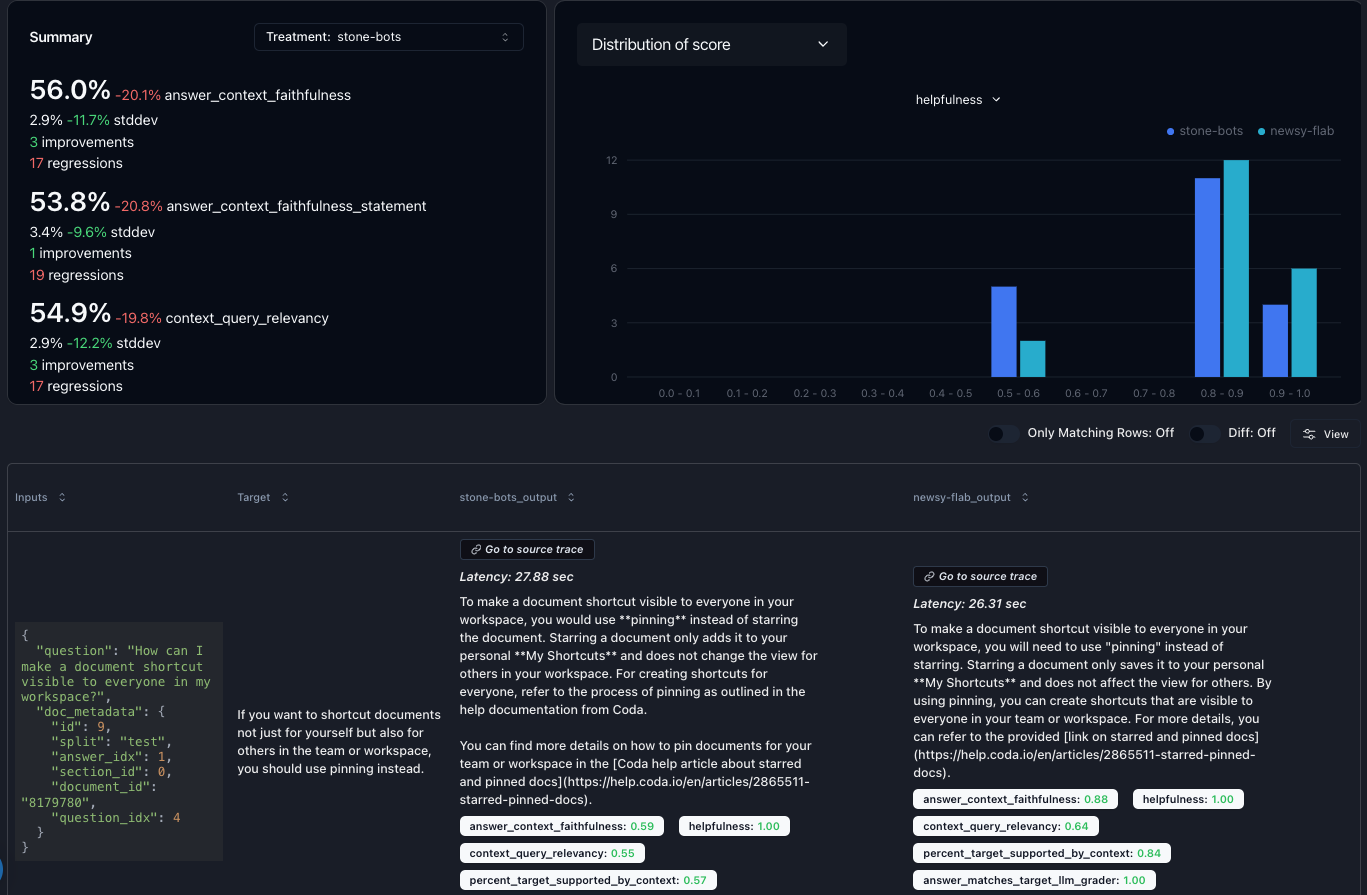
Use an observability tool to collect real user questions and responses. It’s okay if you aren’t collecting feedback yet; first, you want a diverse dataset to iterate on. Tools like Parea can simplify this process. Use our py/ts SDK to quickly instrument your code, and then use your logs to create a dataset. The next step is to establish an evaluation metric.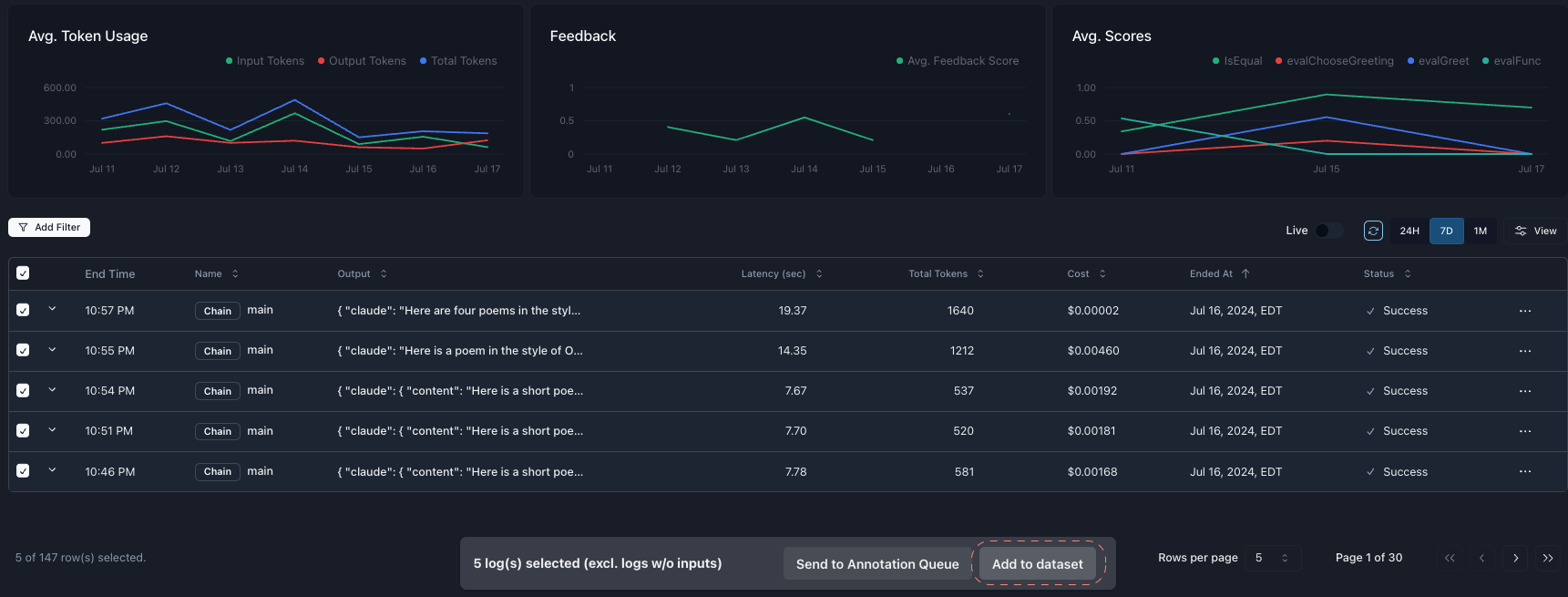
- Relevance: How well does the retrieved information match the query?
- Faithfulness: Does the generated response accurately reflect the retrieved information?
- Coherence: Is the response well-structured and logically consistent?
python
3. Experimentation and Iteration
With your dataset and evaluation metrics in place, it’s time to experiment. Identify the variables you can adjust, for example:- Prompt variations
- Chunking strategies for RAG
- Embedding models
- Re-ranking techniques
- Foundation model selection