We help companies build & improve their AI products with our hands-own
services. Request a consultation
here.
Sample app: finance chatbot
A simple chatbot over the AirBnB 10k 2023 dataset will lend itself as our sample application. We will assume that the user only writes keywords to ask questions about AirBnB’s 2023 10k filing. Given the user’s keywords, we will expand the query. Then use the expanded query to retrieve relevant contexts which are used to generate the answer.Pseudocode of the sample app
Pseudocode of the sample app
Checkout the pseudocode below illustrating the structure:
Tactic 1: QA of every sub-step
Assuming a 90% accuracy of any step in our AI application, implies a 60% error for a 10-step application (cascading effects of failed sub-steps). Hence, quality assessment (QA) of every possible sub-step is crucial. It goes without saying that testing every sub-step simplifies identifying where to improve our application. How to exactly evaluate a given sub-step is domain specific. Yet, you might want to check out these lists of reference-free and referenced-based eval metrics for inspiration. Reference-free means that you don’t know the correct answer, while reference-based means that you have some ground truth data to check the output against. Typically, it becomes a lot easier to evaluate when you have some ground truth data to verify the output.Applied to sample app
Evaluating every sub-step of our sample app means that we need to evaluate the query expansion, context retrieval, and answer generation step. In tactic 2, we will look at the actual evaluation functions of these components.With Parea
Parea helps in two ways with this step. It simplifies instrumenting & testing a step as well as creating reports on how the components perform. We will use thetrace decorator for instrumentation and evaluation of any step.
This decorator logs any inputs, output, latency, etc., creates traces (hierarchical logs), executes any specified evaluation functions to score the output and saves their scores.
To report the quality of an app, we will run experiments.
Experiments measure the performance of our app on a dataset and enable identifying regressions across experiments.
Below you can see how to use Parea to instrument & evaluate every component.
Sample visualization of logged trace
Sample visualization of logged trace
Below is a sample visualization. You can see the scores of a span and its children in the bottom right corner.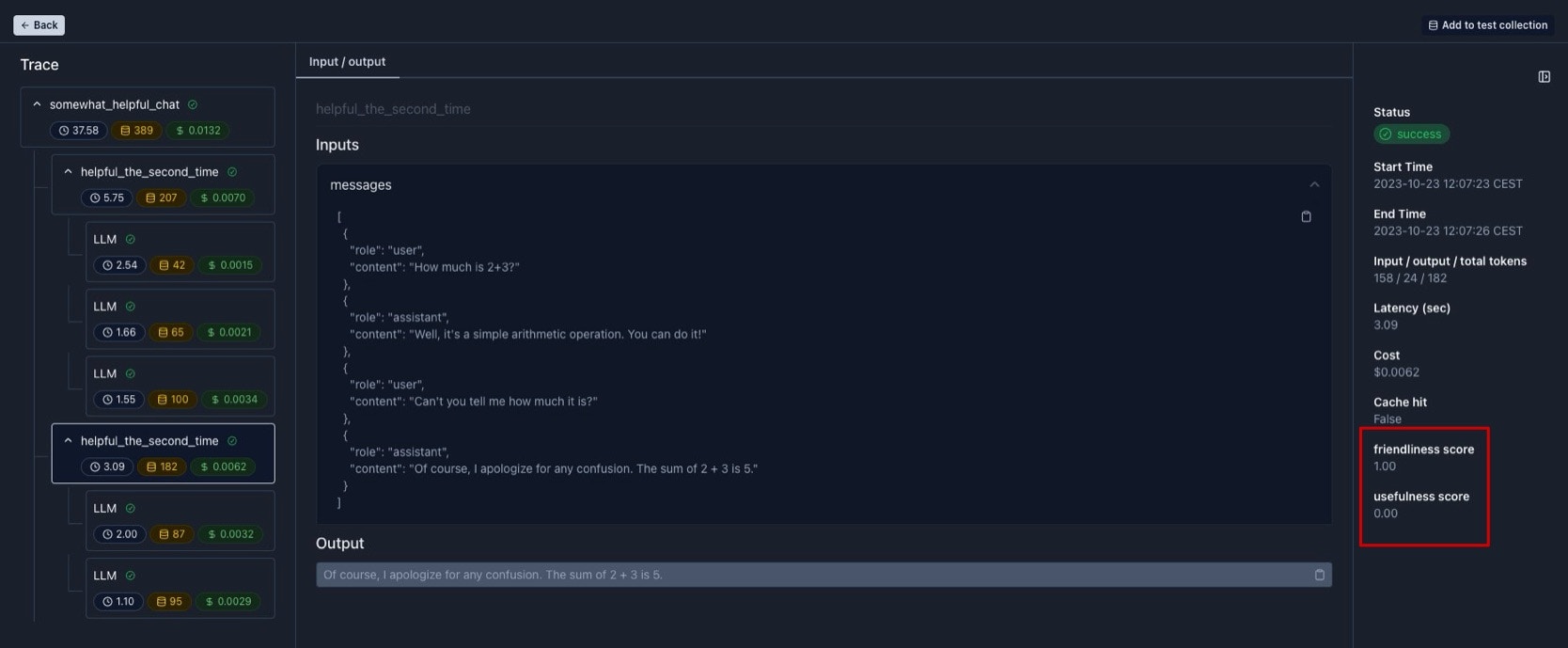
Tactic 2: Reference-based evaluation
As mentioned above, reference-based evaluation is a lot easier & more grounded than reference-free evaluation. This also applies to testing sub-steps. Using production logs as your test data is very useful. You should collect & store them with any (corrected) sub-step outputs as test data. For the case that you do not have ground truth/target values, esp. for sub-steps, you should consider synthetic data generation incl. ground truths for every step. Synthetic data also come in handy when you can’t leverage production logs as your test data. To create synthetic data for sub-steps, you need to incorporate the relationship between components into the data generation. See below for how this can look like.Applied to sample app
We will start with generating some synthetic data for our app. For that we will use Virat’s processed AirBnB 2023 10k filings dataset and generate synthetic data for the sub-step (expanding the keyword into a query). As this dataset contains triplets of question, context and answer, we will do the inverse of the sub-step: generate a keyword query from the provided question. To do that, we will use Instructor with the OpenAI API to generate the keyword query.Generate synthetic data using instructor
Generate synthetic data using instructor
Python
- query expansion: Levenshtein distance between the original question from the dataset and the generated query
- context retrieval: hit rate at 10, i.e., if the correct context was retrieved in the top 10 results
- answer generation: Levenshtein distance between the answer from the dataset and the generated answer
With Parea
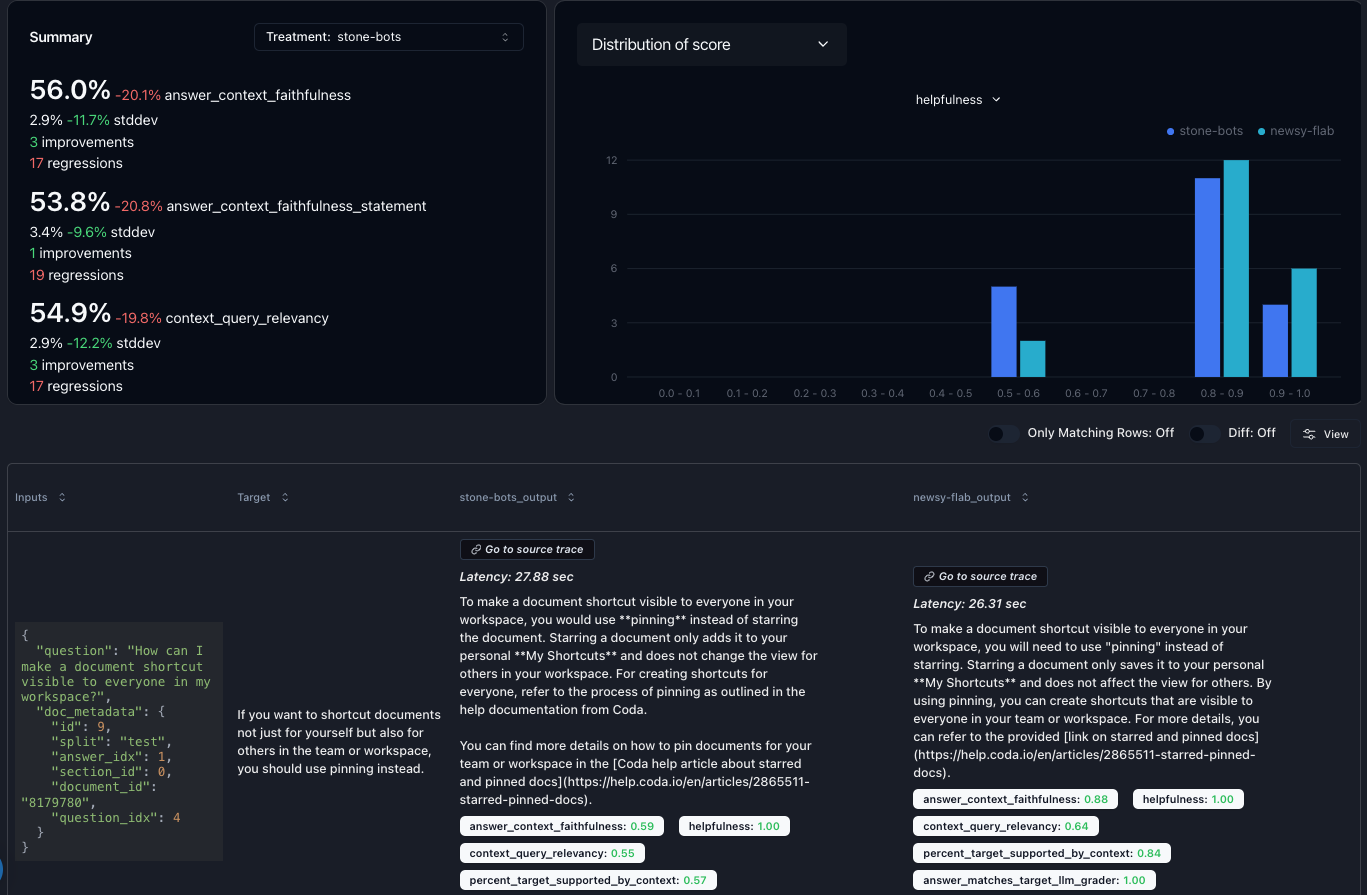
Using the synthetic data, we can formulate our evals using Parea as shown below. Note, an eval function in Parea receives aLog object and returns a score.
We will use the Log object to access the output of that step and the target from our dataset.
The target is a stringified dictionary containing the correctly expanded query, context, and answer.
Tactic 3: Cache LLM calls
Once, you can assess the quality of the individual components, you can iterate on them with confidence. To do that you will want to cache LLM calls to speed up the iteration time & avoid unnecessary cost as other sub-steps might not have changed. This will also lead to deterministic behaviors of your app simplifying testing. Below is an implementation of a general cache:Sample cache implementation
Sample cache implementation
For Python, you can see a slightly modified version of the file caching Sweep AI uses (original code).
Applied to sample app
To do this, you might want to introduce an abstraction over your LLM calls to apply the cache decorator:Summary
Test every sub-step to minimize the cascading effect of their failure. Use the full trace from production logs or generate synthetic data (incl. for the sub-steps) for reference-based evaluation of individual components. Finally, cache LLM calls to speed up & save cost when iterating on independent sub-steps.How does Parea help?
Using thetrace decorator, you can create nested tracing of steps and apply functions to score their outputs.
After instrumenting your application, you can track the quality of your AI app and identify regressions across runs using experiments.
Finally, Parea can act as a cache for your LLM calls via its LLM gateway.