
We help companies build & improve their AI products with our hands-own
services. Request a consultation
here.
- Hill climb your data: Iterate on your application to understand your data & find ground truth values/targets.
- Hill climb your app: Iterate on your application to find a compound system fitting all targets.
Phase 1: Hill climb your data
Your goal in this phase is to find the best ground truth values/target for your data. You do that by iterating on your LLM app and judge if the new the outputs are better, i.e. you continuously label your data. So, taking the example of summarization. To have some ground truth values, you can use a simple version of your LLM app on your unlabeled dataset to generate initial summaries. After manually reviewing your outputs, you will find some failure modes of the summaries (e.g. they don’t mention numbers). Then, you tweak your LLM system to incorporate this feedback and generate a new round of summaries. Now you are getting into hill-climbing mode. As you compare the newly generated summary with the ground truth summary (the previous one) for every sample, update the ground truth summary if necessary. During that pairwise comparison, you will get insights into the failure modes of your LLM app. You will then update your LLM app to address these failure modes, generate new summaries, and continue hill-climbing your data. You can stop this phase once you don’t improve your summaries anymore. Summarizing in a diagram: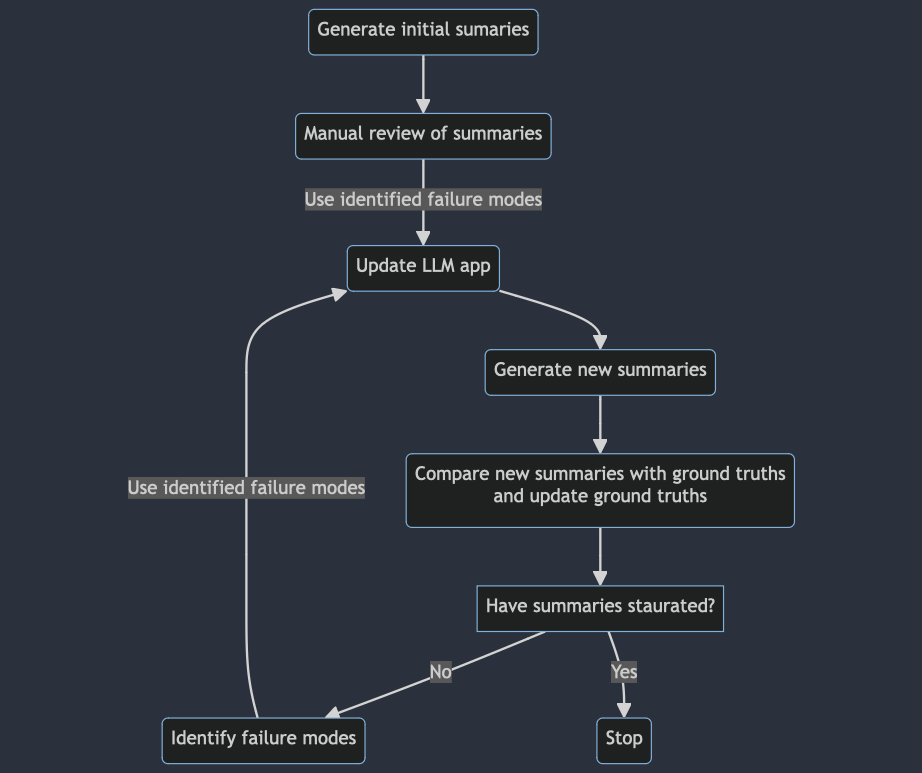
Hill climb your data
This process is akin to how the training data for Llama2 were created. Instead
of writing responses for supervised finetuning data ($3.5 per unit),
pairwise-comparisons ($25 per unit) were used. Watch Thomas Scialom, one of
the authors, talk about it
here.