We help companies build & improve their AI products with our hands-own
services. Request a consultation
here.
The Dataset
We’ll use the Asclepius Clinical Notes dataset of synthetic physician summaries from clinical settings. Paired with those settings are questions about the summary and answers to those questions.
- A note about the medical situation
- A question about the medical situation. An example might be, “Based on the note, what treatment plan did the doctor prescribe for x.”
- The answer to that question
- A task categorization to indicate what the question is asking (e.g., provide a simplified paraphrase (Paraphrasing) vs answer a question about the note (Q&A)).
- Since the data is synthetic and clinical, it’s unlikely to appear in the training dataset for the embedding models.
- Measuring the performance of the embedding model on the Paraphrasing subset means assessing how well the embedding model clusters texts that express the same content. Measuring the performance on the Q&A subset means assessing how well the embedding model clusters related texts/content together. The latter assessment is predictive for using the embedding model to retrieve FAQs to power a chatbot.
The Embedding Models Used for Retrieval
We’ll define our retrieval system using BAAI’s bge-base-en-v1.5 and OpenAI’s embedding models. From OpenAI, we’ll use concretely:- text-embedding-ada-002 - which is their previous generation
- text-embedding-3-small - with embedding dimensions 512 and 1536
- text-embedding-3-large - with embedding dimensions 256 and 3072
Reference-free evaluation of Hit Rate of a retrieval system
An LLM-based eval metric is an easy way to measure a retrieval system’s hit rate without access to the correct answer (i.e “reference-free”). We can use a zero-shot prompt which instructs the model to assess whether the answer to a given question is among a list of answers. To have parseable outputs, we can use JSON mode to instruct the model to return a field calledthoughts (which gives the model the ability to think before deciding)
and a field called final_verdict (which is used to parse the decision of the LLM).
This is encapsulated in Parea’s pre-built LLM evaluation (implementation
and docs), which leverages gpt-3.5-turbo-0125 as the default LLM.
To improve the accuracy of the LLM-based eval metric, few-shot examples are used. We select these samples:
- example 1: an example where jina-v2-base-en didn’t retrieve the correct answer for a Q&A task
- example 2: an example where bge-base-en-v1.5 didn’t retrieve the correct answer for a paraphrasing task
0_shot1_shot_false_sample_1- Enhances
0_shotwith few-shot example 1
- Enhances
1_shot_false_sample_2- Enhances
0_shotwith few-shot example 2
- Enhances
2_shot_false_1_false_2- Enhances
0_shotwith first few-shot example 1, then 2
- Enhances
2_shot_false_2_false_1- Enhances
0_shotwith first few-shot example 2, then 1
- Enhances
Experiments
A bit meta: evaluating our evals
To assess how well our evals align with hit rate, we are assessing a binary classification task (“Did the evaluation agree with the measured hit rate?”). So, we can use accuracy to quantify the performance of the evals, i.e., the percentage of how often the new eval agrees with the hit rate.Experiment setup
We will benchmark each eval metric for each task subset and embedding model to correctly assess hit rate on 400 randomly selected samples. For that, we will follow these steps:-
Use Lantern to embed each data entry of the task subset with the respective embedding model in two parts
- Embed the question as a vector
- Embed the answer as a vector
-
Use Parea’s SDK to execute the experiment, i.e., perform the following steps:
- Define a function that, given a question and task category, searches the answer column of the task subset for the top 20 approximate nearest neighbors (ANNs) using the vector representation of that question (code).
- Define evaluation metrics that are applied to every sample’s output to calculate
- Hit rate @ 20 - Measures if the correct answer appears in the top 20. This is a binary yes/no result. A higher average is better (code).
- The LLM-based evaluation metrics as described in above section (code).
- Create and run the experiment, which applies the above function and applies it over 400 random samples dataset (code).
The results
The graph below shows how well each evaluation metric aligns with the measured hit rate. While the 0-shot pre-built evaluation metric achieves 83% on the Q&A subset (blue color), it only reaches 53% on the Paraphrasing subset (orange color). Note that the average retrieval performance on Q&A is 83% and is 58% on Paraphrasing. This means that the pre-built evaluation metric is well-suited for systems which are ready for production, but not if you’re still trying to improve performance on your labeled data. Adding few-shot examples doesn’t improve performance and can even hurt it on the Q&A subset. On the other hand, we can see how adding one few-shot example increases the accuracy on the Paraphrasing subset by 22% (2nd and 3rd bar). While combining them is synergistic and can improve the accuracy of the eval metric to 81% (4th bar), their order matters a lot (compare 4th & 5th bar).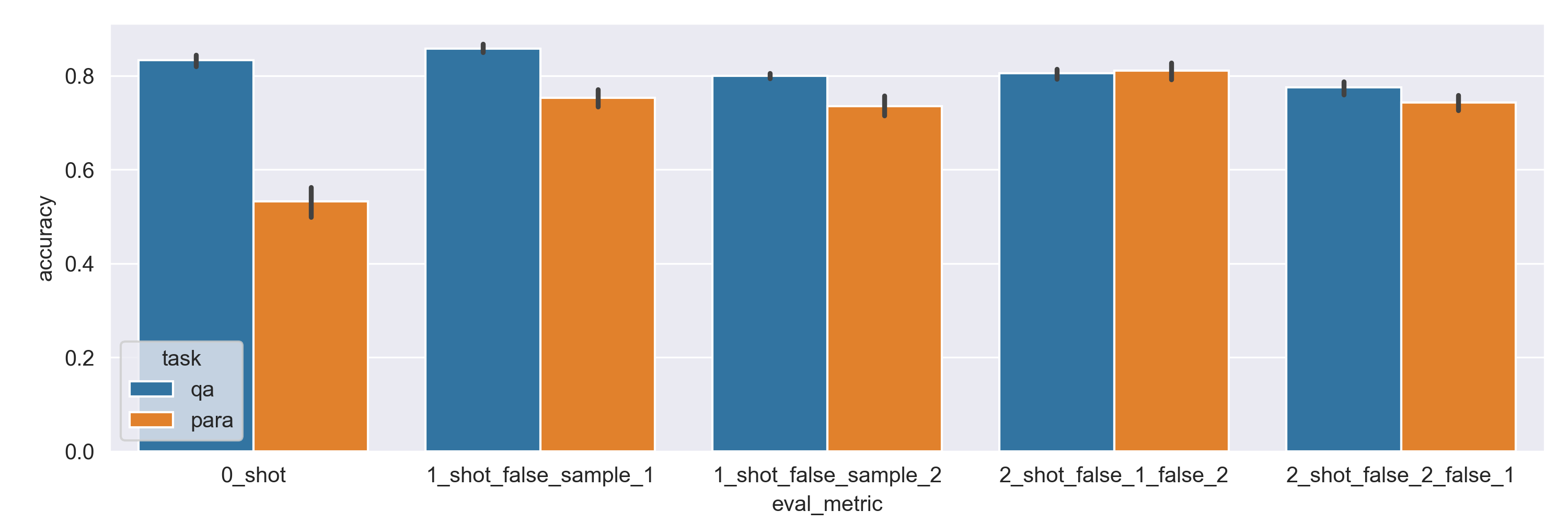
thoughts field in the response.
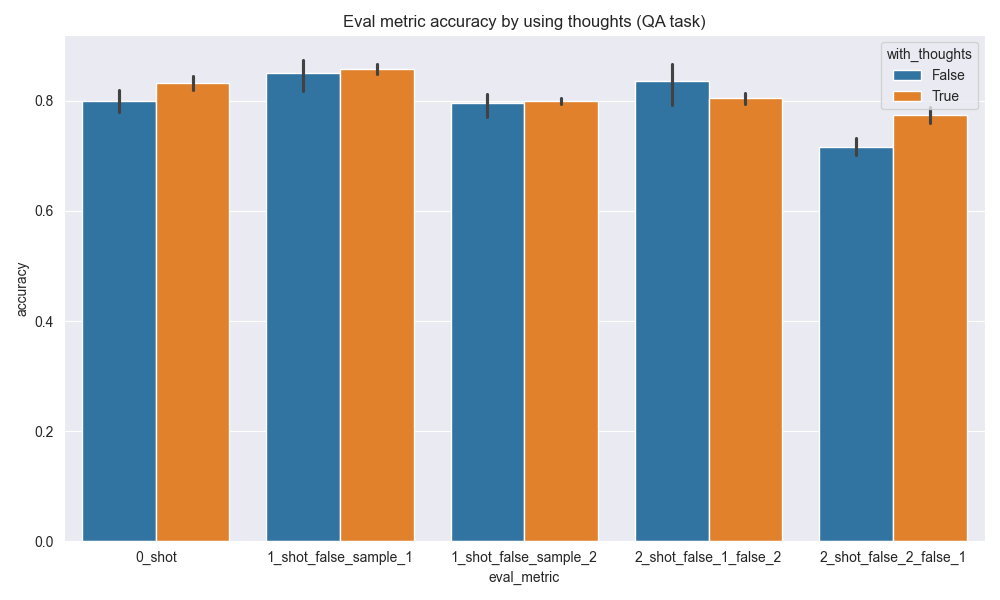
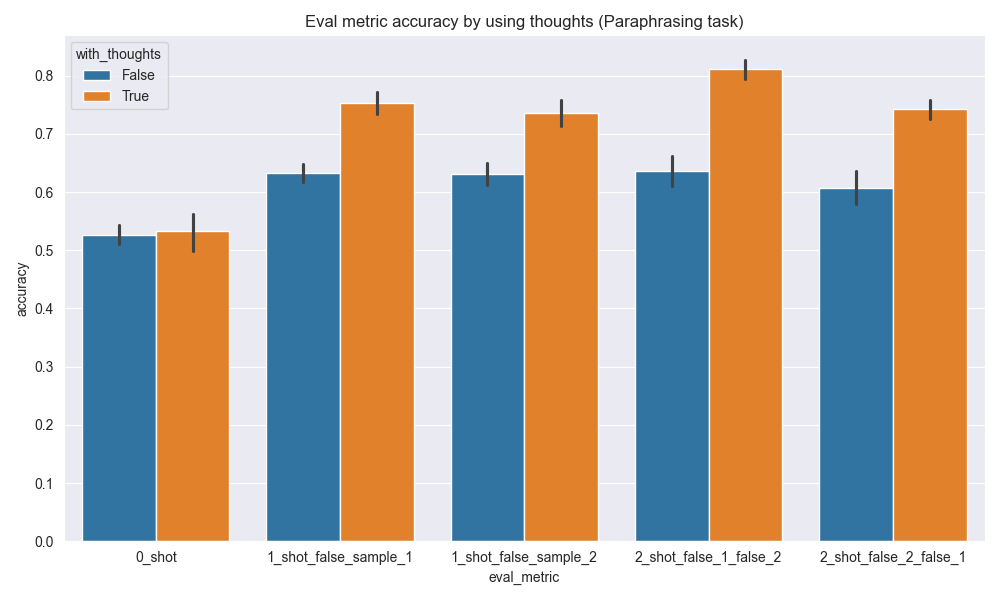
In the bar plots below, you can see the effect on the accuracy of the eval metric when not using the thoughts field (blue) and when using the thoughts field (orange).
While there is a positive effect on the Q&A subset (1st plot below), the effect is less pronounced than on the Paraphrasing subset (2nd plot below), where improvements are up to 17% in absolute accuracy (4th bar).
In particular, it’s interesting how the effectiveness of chain-of-thought increases when adding few-shot examples (bars 2 to 4 in lower plot).