We help companies build & improve their AI products with our hands-own
services. Request a consultation
here.
The Setup
I downloaded the CSV of prime numbers from the paper for benchmarking. I realized that although the paper shared the prompt,Is {{number}} a prime? Think step by step and then answer "[Yes]" or "[No]., it didn’t state whether it
was a system or user message. To cover my bases, I tried both. The paper used a temperature of 0.1 which seemed oddly
specific, so to make the experiments more deterministic, I tested both 0.1 and 0.0. Alas, to save my wallet, I
constrained myself to the GPT-3.5-turbo model.
Evaluating LLM BehaviorDrift
I used Parea’s platform to facilitate my testing. Using Parea’s Datasets tab, I uploaded the CSV as a test collection and built custom evaluation metrics. A common challenge with LLMs is coercing them to abide by strict output schemas. For example, the paper’s prompt says to answer “[Yes]” or “[No],” but their evaluation criteria only requires the model’s response to contain “yes.” Having read of the positive impact of relaxing parsing requirements on LLM performance for LeetCode questions, read more here, I decided to test two evaluation variants:- A Fuzzy version - Give a score of 1 if “yes” is in the response (same as the paper)
- A Strict version - Give a score of 1 only if “[yes]” (with the brackets) is in the response
Observations
Using Parea’s benchmark feature, I could test all variants of my prompts against the different prime number test cases and with various evaluation metrics. Below is a summary table of the benchmarking exercise using a temperature of 0.1, like in the paper. The first two rows are metrics for GPT-3.5-turbo-0301 (March snapshot), and the last two are for GPT-3.5-turbo-0601 (June snapshot).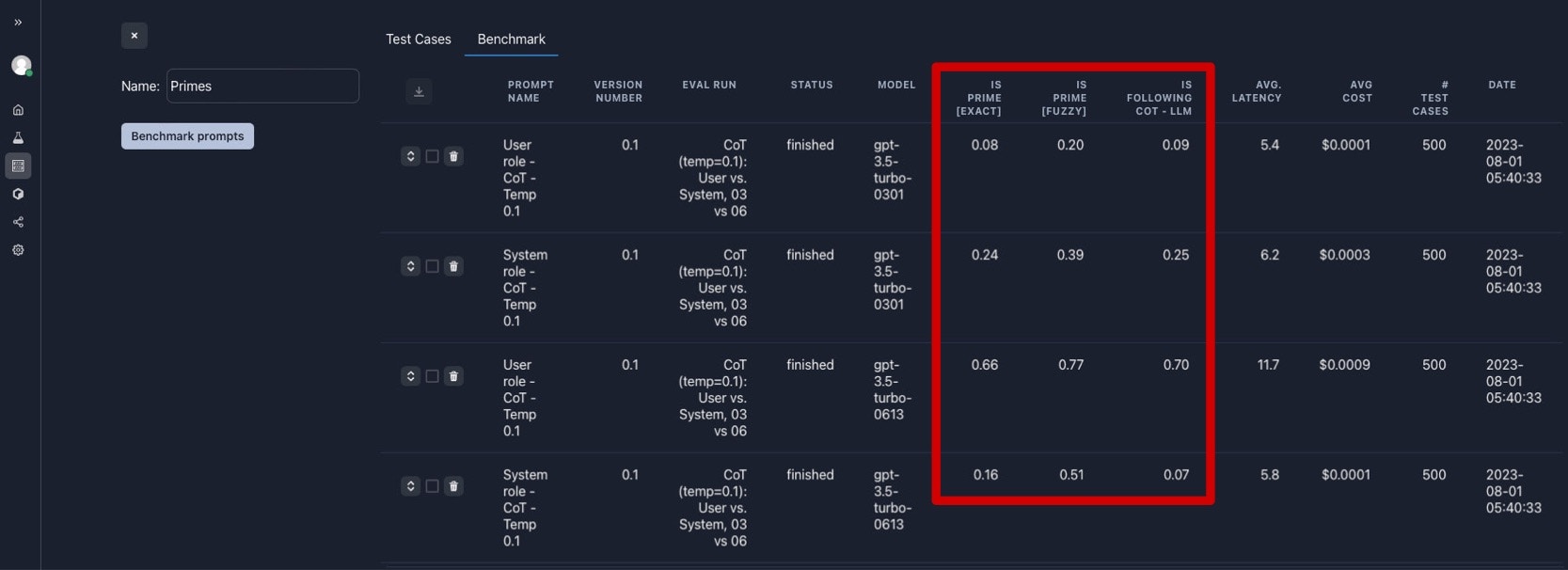
Benchmark overview comparing using user or system roll for the March (top 2 rows) and June snapshot (bottom 2 rows) for GPT-3.5-turbo.
Conclusion
I agree with the paper that OpenAI’s fine-tuning process caused changes in model performance from March to June. However, the direction of that drift is unintuitive and inconsistent. With all prompt engineering, building intuition on what may drive model performance is helpful. Using multiple evaluation metrics is one way to build this intuition (e.g., measuring if CoT instructions are followed or if answers respect given formats). I open-sourced the results and evaluation metrics in this GitHub repository. You can easily use any of these metrics on Parea or create your own and do experiments like this one. I’m excited to see what others will find when investigating model behavior!Test Prompts with Parea
Prompt Playground
Compare, version, test, and evaluate prompts