We help companies build & improve their AI products with our hands-own
services. Request a consultation
here.
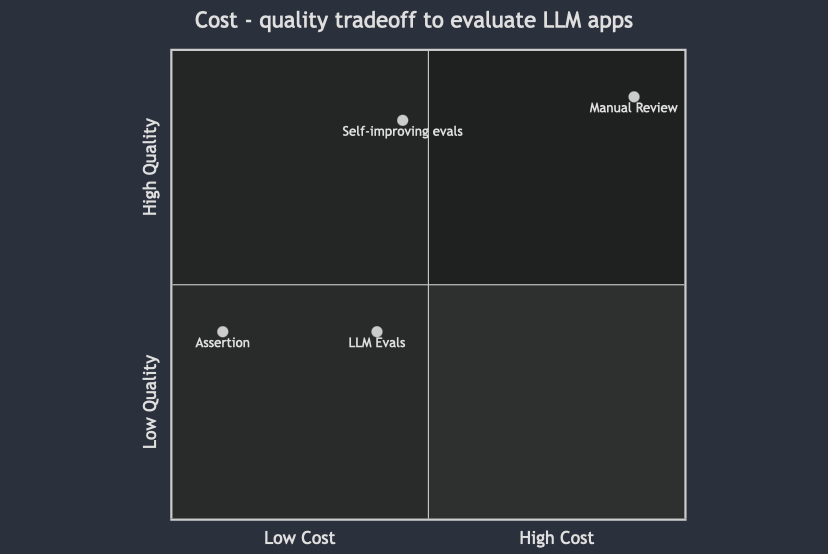
Seeing it in action: Judge Bench
Recently, JudgeBench introduced a collection of datasets which measured how well LLMs can evaluate outputs. This is a great opportunity to test our approach. We tested it on 2 of the datasets. For each dataset and annotation criterion for that dataset, we split the data into training and testing samples. Then, we applied the new feature to the training samples to find an optimal prompt to mimic human annotators. For all datasets, we used 25 randomly chosen training samples and reported Cohen’s kappa coefficient on the remaining samples. Also, we usedgpt-3.5-turbo-0125 as evaluator.
| Dataset | gpt-4o [JudgeBench] | Our Approach |
|---|---|---|
| cola | 0.34 | 0.57 |
| Toxic Chat - Toxicity | 0.73 | 0.63 |
| Average | 0.54 | 0.60 |