Creating Aligned LLM Evals
There is an end-to-end example with video at the end of this page.
Selecting the right annotation criteria
It’s recommended to use annotation criteria which assess one pattern of failure / failure mode. If the evaluation of an annotation is too complex / multi-faceted, it’s better to break it down into multiple annotation criteria. This makes it easier for the annotator to annotate as well as for the LLM to learn that annotation with fewer data. E.g. in the context of summaries you would use criteria for coherence, coverage, etc. instead of a single evaluation for the whole summary. Hence, it’s recommended to review logs before creating the annotation criteria to gain an intuition of the patterns of failure.Triggering the creation of the LLM eval
Once you open an annotation criterion from the annotations page, click on “Create LLM Eval”. If you have 20 or more logs annotated for that annotation criterion, you can trigger the creation of the LLM eval by clicking “Create LLM Eval” on the card which appears. If you have less than 20 logs annotated, you can either annotate more logs or upload a CSV file.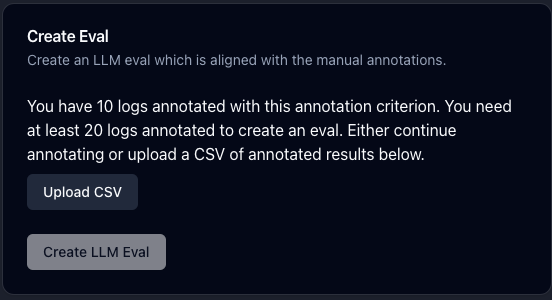
Uploading a CSV file of annotations
The CSV file should contain columns for any inputs used to generate the output, the output itself and the annotation of that output. After uploading the CSV file, you can choose which columns are mapped to be aninput, the output and the annotation.
Note, there must be exactly one column mapped to output and one to annotation.
Additionally, the annotation needs to match the annotation criterion.
That means for categorical annotations, the annotation column can only take values as the defined categories, and for continuous annotation, the column needs to be a number between the min. and max. score (incl.).
Running Aligned LLM evals
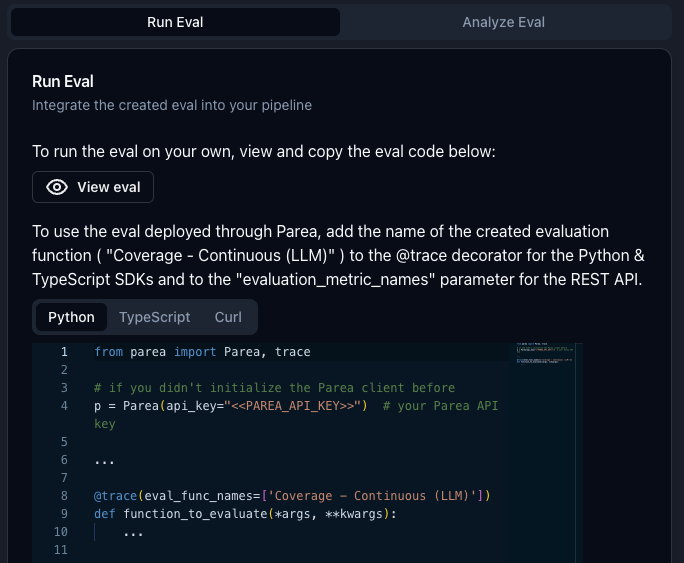
After the LLM eval has been created, you can view its source code (Python) which you can copy-paste into your own codebase to run the LLM eval. Alternatively, you can also run the eval deployed through Parea by including the annotation name with the postfix ” (LLM)” in theevaluation_metric_names (Python & Curl) / evalFuncNames (TypeScript) parameter of the trace decorator / REST API call.
So, if the annotation criterion is named “coherence”, the LLM eval would be named “coherence (LLM)”.
When you add the eval to the trace decorator or REST API call, Parea will automatically execute the eval on that log.
Below you can see an in-app screenshot of how to run the LLM eval.
Analyzing Aligned LLM evals
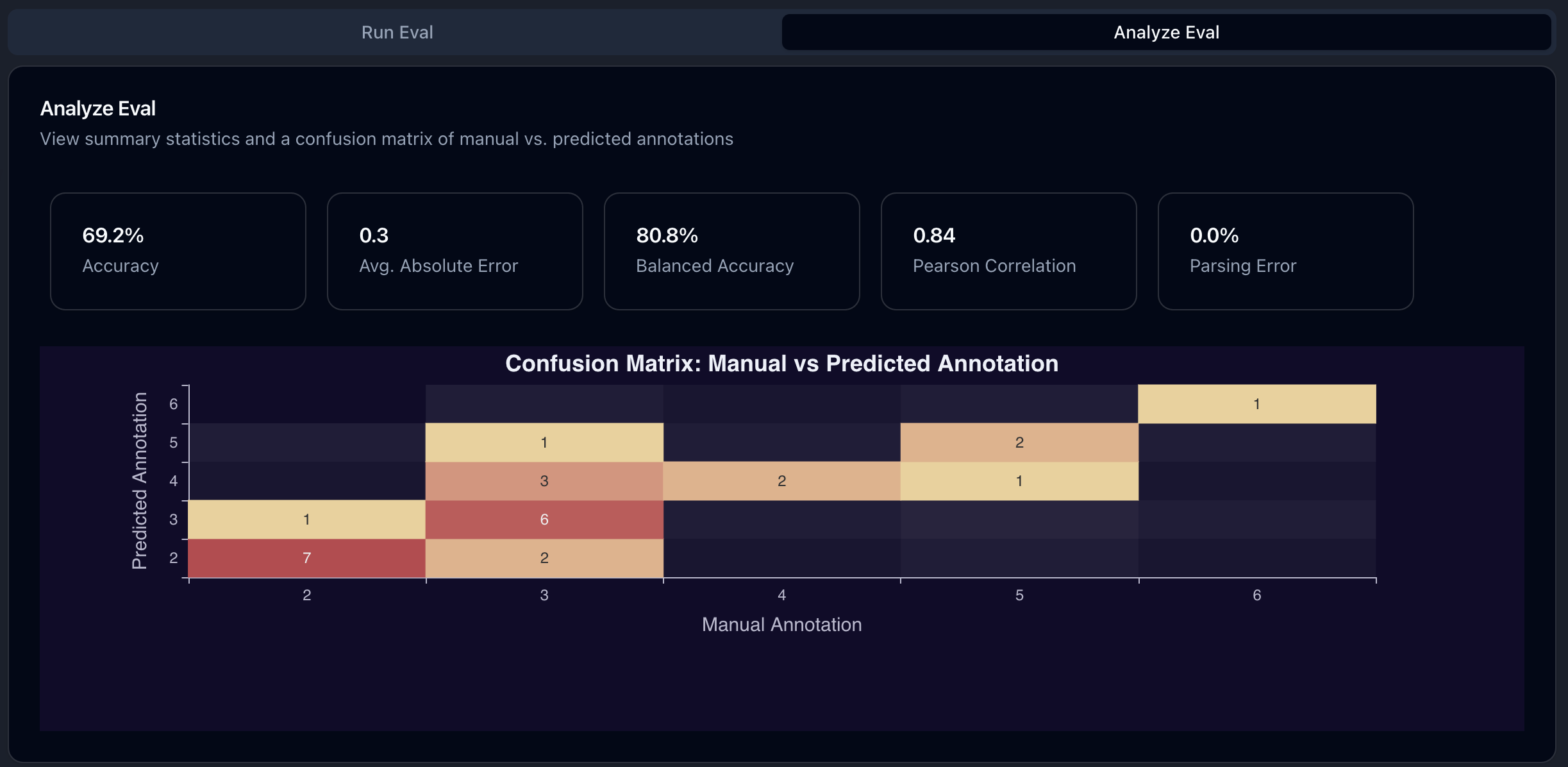
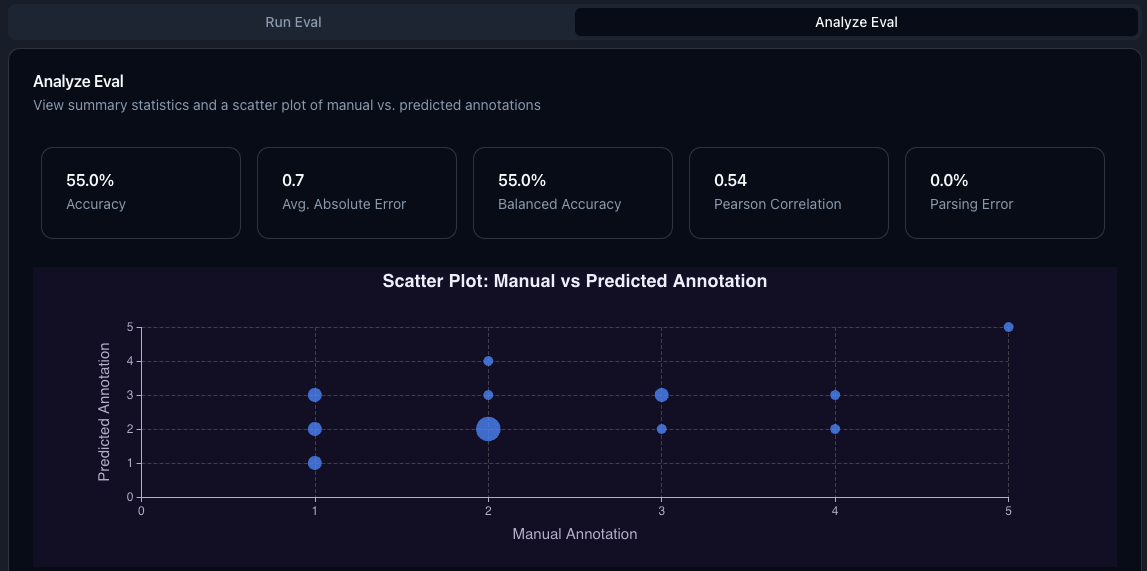
After the eval has been created, you can analyze its performance by clicking on theAnalyze Eval tab.
In that you will see summary statistics such as (balanced) accuracy, Pearson correlation, and average absolute error.
Additionally, you can see either a confusion matrix or a scatter plot of the manual vs. LLM judge annotation.
A confusion matrix will be shown if the annotation criterion is categorical or continuous with less than 11 unique values.
Example: Create a LLM eval to assess coverage of summaries of Reddit posts
To demonstrate how this works, we will use human annotations of generated summaries of the TL;DR Reddit dataset which was done as part of the Learning to summarize from human feedback paper by OpenAI. We will use 20 annotated samples from the dataset to create an LLM eval which assesses the coverage of the summaries. You can find the dataset here. In the video below we will first create an annotation criterion, then upload a CSV of annotations, create a LLM eval and finally show the confusion matrix of the LLM eval.
After following along the above video, we get the following results (the avid reader might notice that these are the same results as in the screenshot above):
Run Eval tab.