Getting started
For any model you want to use with the SDK, set up your Provider API keys.
Create New Session.
TLDR: Write your prompt, use {{}} to define template variables. Fill in the input values and click Compare 🎉!
Parea’s prompt playground is a grid where your prompt templates are the columns, and the template inputs are the rows.
Every time you change prompt parameters and run an inference, a new prompt version is created, making it easy to track
all prompt changes and compare different versions.
Components of Parea’s Playground
The playground allows you to compare multiple prompts against multiple input values. You can click the Compare button to run all prompts, or optionally run a specific prompt against the inputs (run column), run all prompts against a specific input (run row), or run only one prompt/input pair (run cell).Prompt
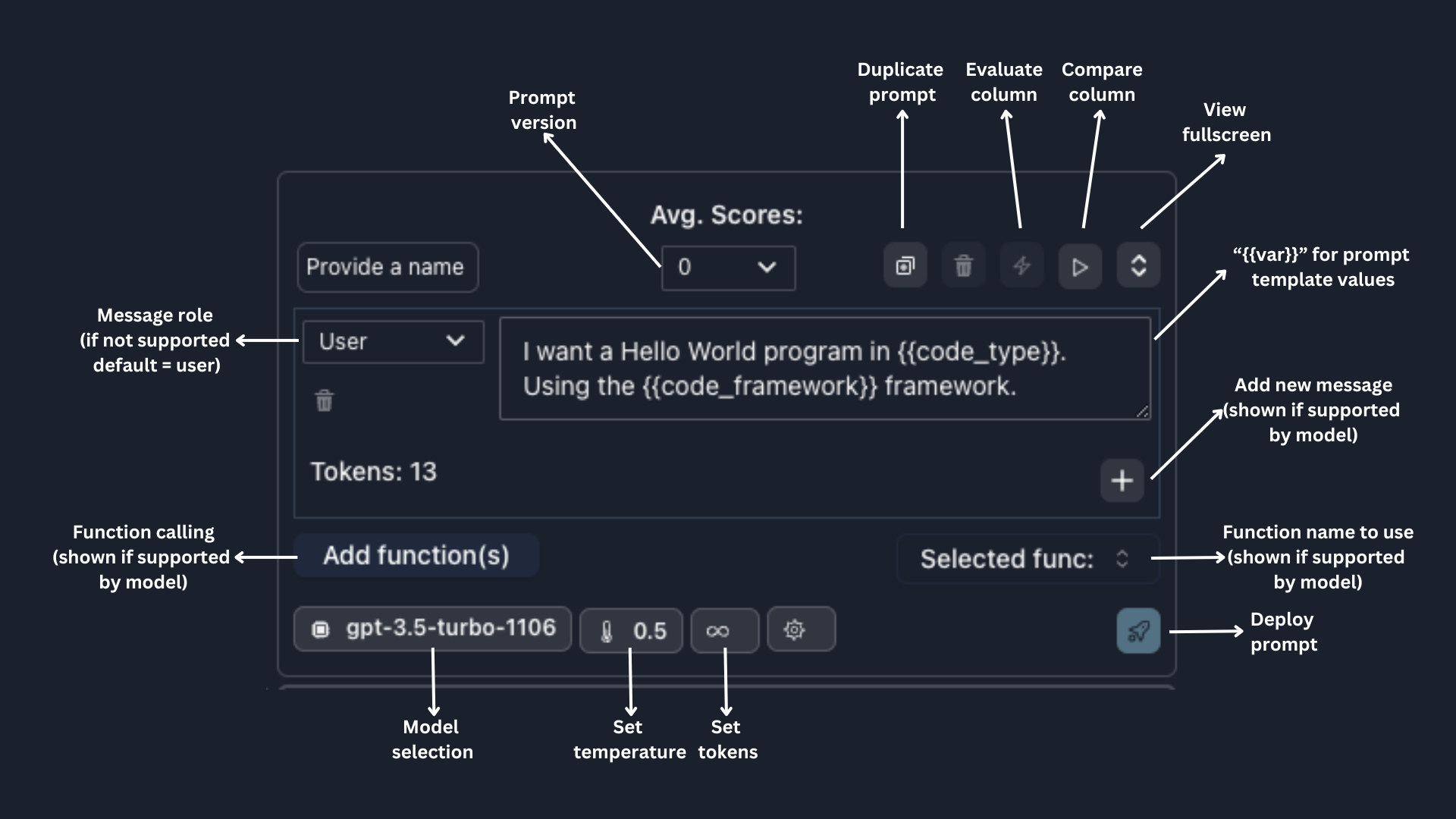
{{}}.
Template variables will automatically appear as input rows; the values will be interpolated at runtime.
The prompt section is flexible for various LLM models.
For models that support multiple messages and roles, such as OpenAI models, Claude 2.1 (with system message role),
and Anyscale’s OSS models, you will be able to add new messages and define the roles; Parea will handle the proper
prompt formatting in the background.
For models that support function calling, such as OpenAI models and Anyscale’s Mistral-7B-Instruct, you can
click Add Function to either attach an existing function schema or create a new one. Using the selected function,
you can instruct the model to call a specific function, or select auto to allow the model to determine whether to use a function.
Inputs
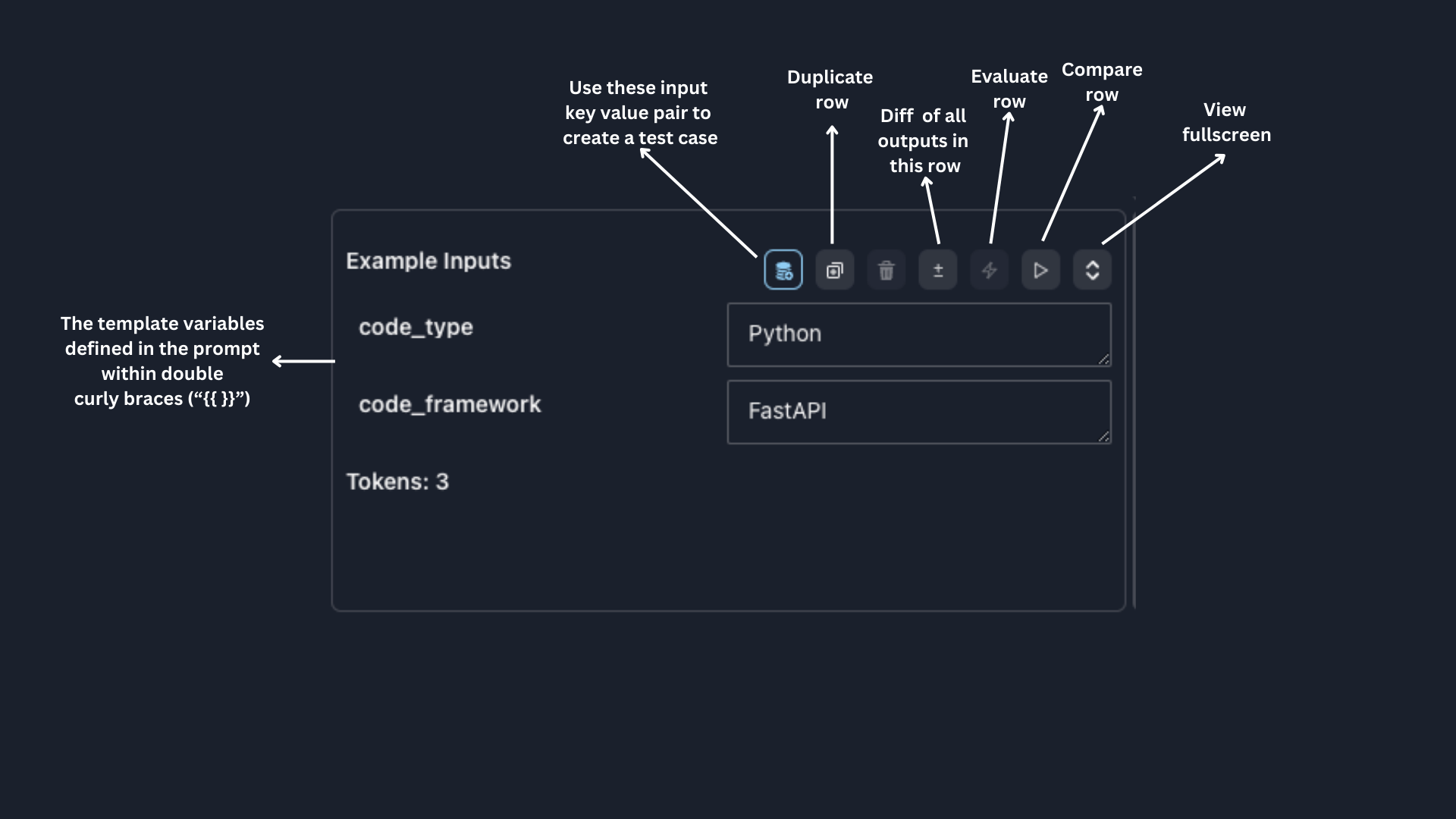
Add to test collection button and optionally provide a target value.
Inference
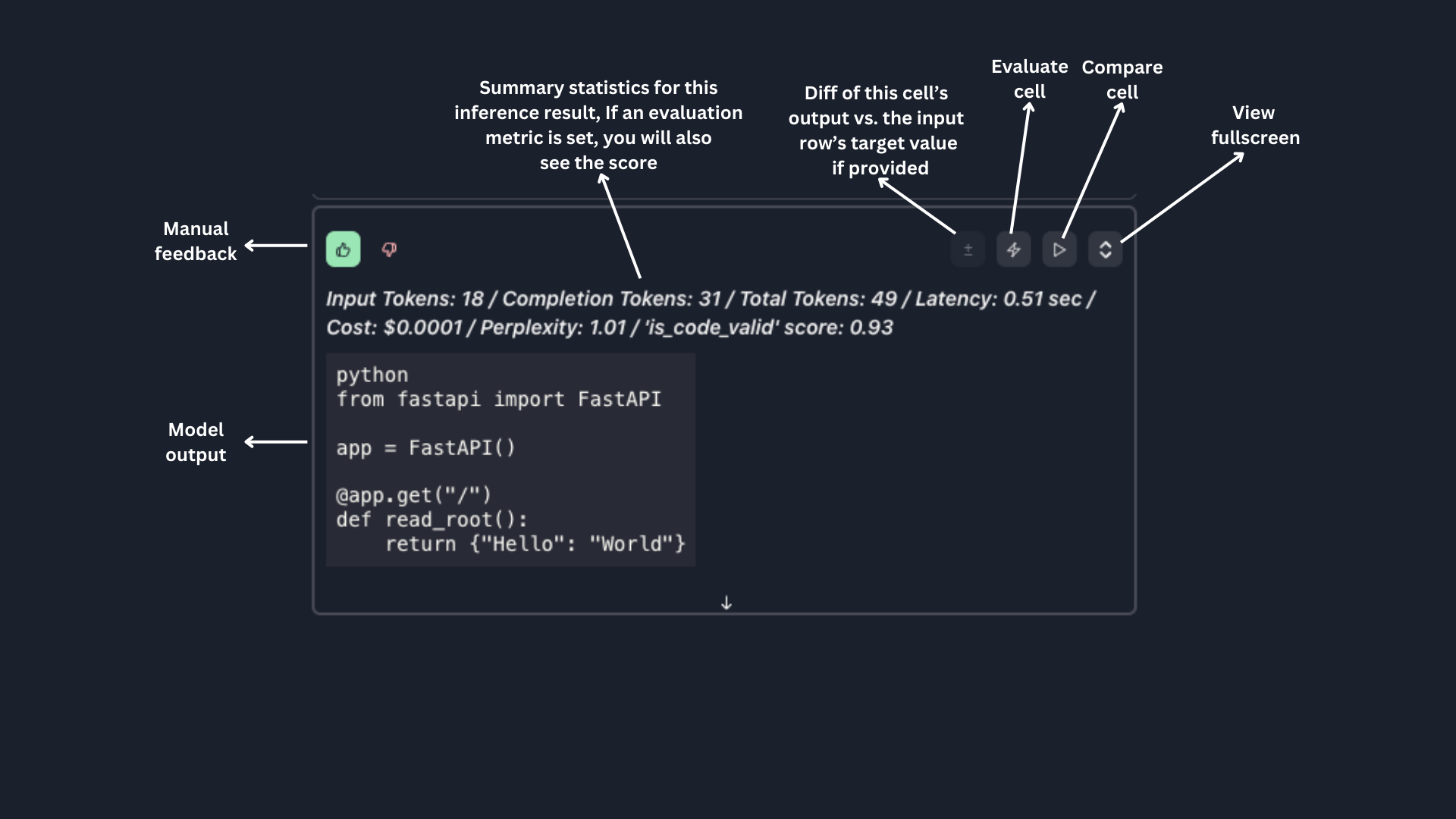
Supported LLM Inference API Provider
We currently support the following LLM inference API providers in the Playground:- OpenAI
- Anthropic
- Azure
- Anyscale
- AWS Bedrock
- Google Vertex AI
- Mistral
- OpenRouter
- LiteLLM Proxy
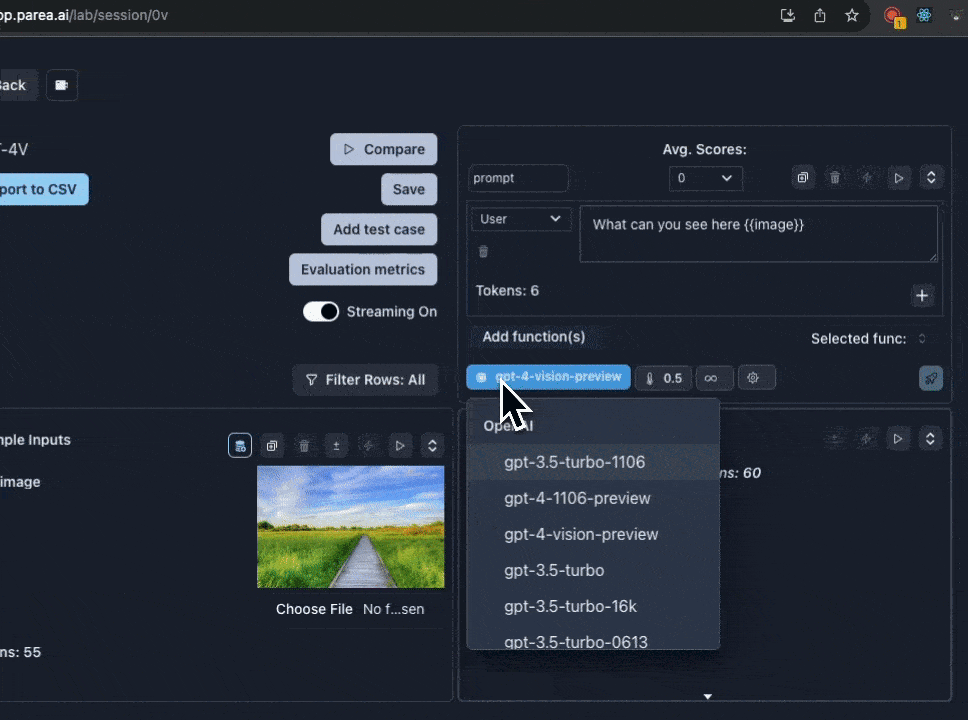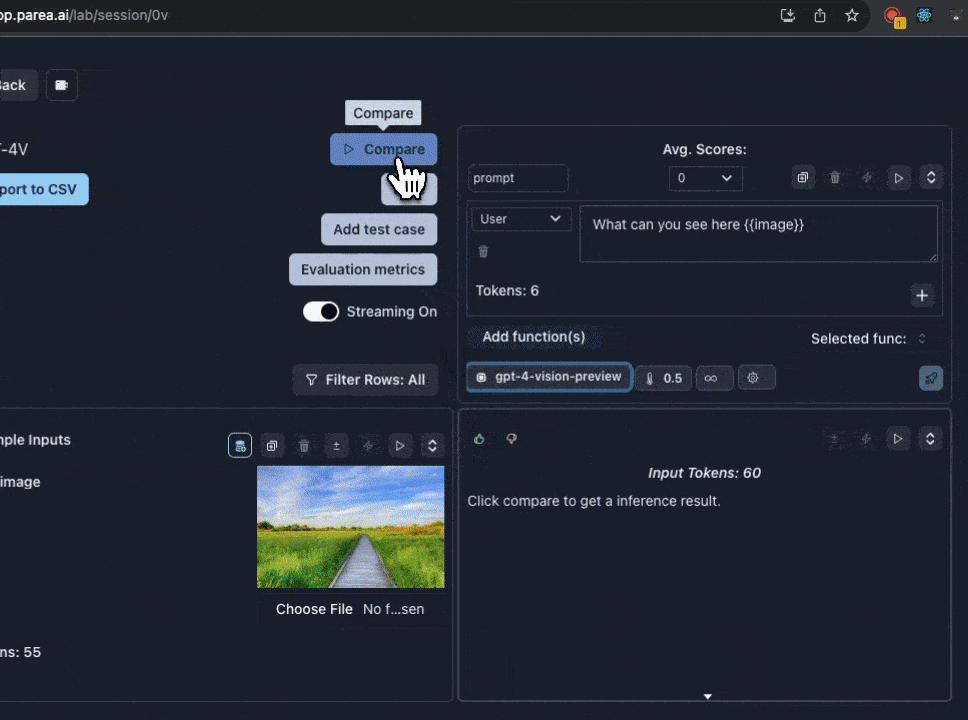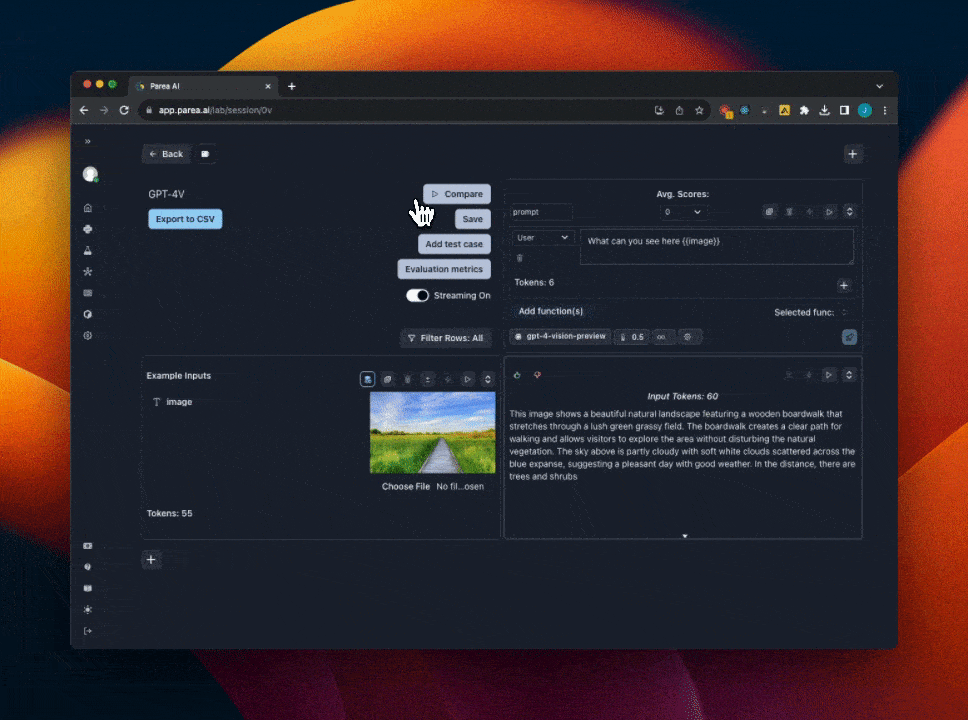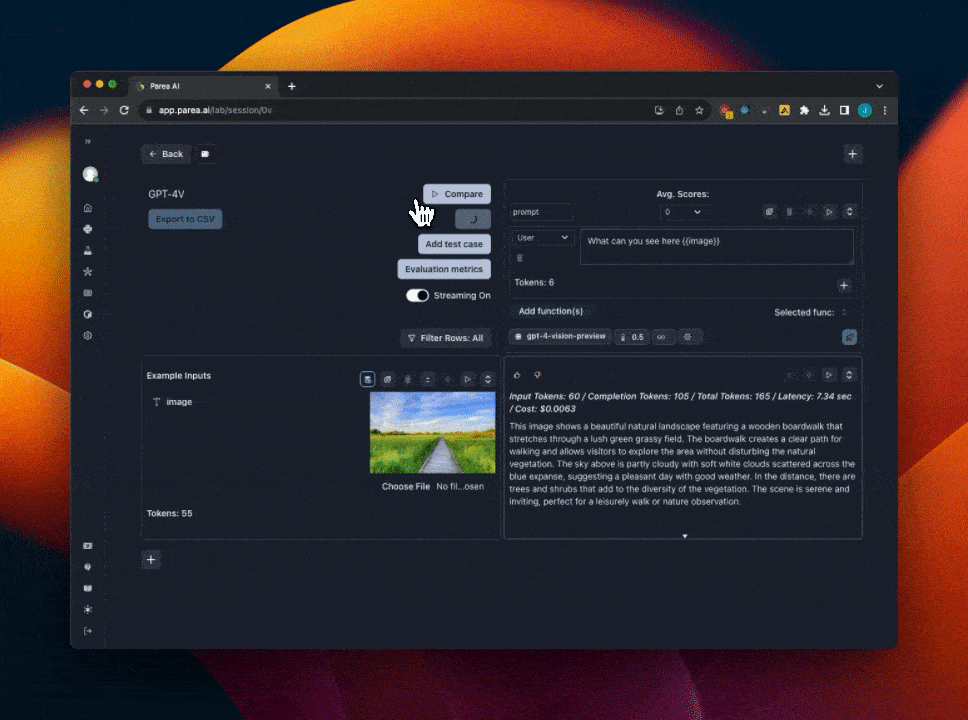
Using GPT-4 Vision
We support experimenting with GPT-4 vision prompts in the Playground. If you already have a Parea account, you can open this templated session to get started. To get started with GPT-4 vision manually:- First, you must have OpenAI API key set in the settings page. And have access to the GPT-4 Vision model.
- Then, select
gpt-4-vision-previewfrom the model dropdown menu. When you select GPT-4 Vision, the input cell will change to support uploading images. - Add a template variable to your prompt to assign to the image. e.g
{{image}} - Click the
image iconnext to the template variable you added to switch to image input mode. - Then click
Choose fileto upload an image
What’s next?
Now that you’ve defined a basic prompt template, we can add more granular functionality.Add functions
Add function calling schema to prompt
Add test cases
Use test cases as prompt template inputs
Add evaluation metric(s)
Add pre-defined or custom evaluation metrics
Deploy prompt
Deployed and access prompt via the SDK