Conceptualizing Testing & Evaluating LLM Applications
Because LLMs have non-deterministic behavior, it’s critical to understand the accuracy of your LLM app while you’re developing, and before you ship. It’s also important to track performance over time. It’s unlikely that you’ll ever hit 100% correctness, but it’s important that for the metrics you care about, you’re steadily improving. Parea’s experiments allow you to capture this into a simple, effective workflow that enables you ship more reliable, higher quality products. To evaluate your LLM app, you need some data (10 samples are sufficient) and a function that executes a task. Your data need to contain the inputs to the function as key-value pairs and can optionally contain a ground truth value for that sample (indicated by the keytarget).
While 10 samples are sufficient to get started, it’s useful to continue to add more samples whenever you identify new failure cases from your production traffic.
The goal of evaluation is to assess each of component and improve them over time.
In practice, it’s better to assume for that your data is noisy, the LLM is imperfect, and evaluation methods are a little bit wrong.
Evaluation Metrics
You can either use pre-built SOTA evaluation metrics or define your own custom evaluation metrics. You can use evaluation metrics by attaching them via thetrace decorator to your function.
This will automatically execute the evaluation metric on the output of the function in non-blocking in the background after the function execution has finished.
You can apply evaluations at any “level” of your application by attaching them to the corresponding function decorated with trace.
This is useful to understand the quality at different levels of granularity (“Was the right context extracted?” vs. “Was the answer correct?”).
Using Pre-built SOTA Evaluations
Parea provides a set of state-of-the-art evaluation metrics you can plug into your evaluation process. Their motivation & research are discussed in the blog post on reference-free and reference-based evaluation metrics. Here is an overview of them:General Purpose Evaluation
General Purpose Evaluation
levenshtein: calculates the number of character-edits in the generated output to match the target and normalizes it by the length of the output; more herellm_grader: leverages a general-purpose zero-shot prompt to rate responses from an LLM to a given question on a scale from 1-10; more hereanswer_relevancy: measures how relevant the generated response is to the given question; more hereself_check: measures how well the LLM call is self consistent when generating multiple responses; more herelm_vs_lm_factuality: uses another LLM to examine original LLM response for factuality; more heresemantic_similarity: calculates the cosine similarity between output and ground truth; more here
RAG Specific Evaluations
RAG Specific Evaluations
context_query_relevancy: calculates the percentage of sentences in the context are relevant to the query; more herecontext_ranking_pointwise: measures how well the retrieved contexts are ranked by relevancy to the given query by pointwise estimation; more herecontext_ranking_listwise: measures how well the retrieved contexts are ranked by relevancy to the given query by listwise estimation; more herecontext_has_answer: classifies if the retrieved context contains the answer to the query; more hereanswer_context_faithfulness_binary: classifies if the answer is faithful to the context; more hereanswer_context_faithfulness_precision: calculates how many tokens in the generated answer are also present in the retrieved context; more hereanswer_context_faithfulness_statement_level: calculates the percentage of statements from the generated answer that can be inferred from the context; more here
Chatbot Specific Evaluations
Chatbot Specific Evaluations
goal_success_ratio: measures how many turns a user has to converse on average with your AI assistant to achieve a goal; more here
Summarization Specific Evaluations
Summarization Specific Evaluations
factual_inconsistency_binary: classifies if a summary is factually inconsistent with the original text; more herefactual_inconsistency_scale: grades the factual consistency of a summary with the article on a scale from 1 to 10; more herelikert_scale: grades the quality of a summary on a Likert scale from 1-5 along the dimensions of relevance, consistency, fluency, and coherence; more here
Custom Evaluations
You can also define your own evaluation metrics. They can be as simple as checking if a certain word is in the output as shown below.log parameter.
All evaluation functions accept the log parameter, which provides all the needed information to perform an evaluation.
Evaluation functions are expected to return floating point scores or booleans.
Log Schema Definition
Log Schema Definition
Skipping Evaluation Metrics
Sometimes it’s useful to apply evaluation metrics only on a subset of the data. For that, you returnNone/null in the evaluation function to skip the evaluation for that log.
Return a Reason
While numerical scores are useful to get a fast grasp of how good a response is, it’s useful to provide a reason for why a response is bad. Especially, if one uses a LLM-based evaluation metric, it’s good to pass on the reasons for why the LLM assigned a certain score. You can do that by returning anEvaluationResult object with a reason attribute.
Updating above example:
EvaluationResult object is as follows:
EvaluationResult Definition
EvaluationResult Definition
Returning Multiple Scores
Sometimes there is shared work between different evaluation metrics such that returning multiple scores is better. You can do that by returning a list ofEvaluationResult objects.
Running & Naming of Experiments
Depending on whether you use Python or TypeScript, you can name & run experiments in the below ways. You need to name an experiment and can optionally specify the name of a particular run. Note, that the run name can only contain alphanumeric characters, dashes, and underscores and needs to be unique within each project. After an experiment is finished, you will see an overview of the average stats and a link to the experiment page with full details.- Python
- TypeScript
In Python, you can define an experiment by calling the Alternatively, you can also use the CLI to run an experiment:In this case the experiment file should contain the experiment definition but not call the
experiment method of the Parea client p and run it by calling the run method of the experiment.
You can optionally specify the name of the run by passing it to the run method.run method. You can optionally specify the run name of the experiment using the --run_name flag in the CLI.Organization of Experiments & Historical Trends of Evals
Within projects, you can organize your experiments by the experiment name. You can filter the experiments table by the experiment name to see all runs of that experiment. This will also filter the graph of historical experiment eval scores by that name.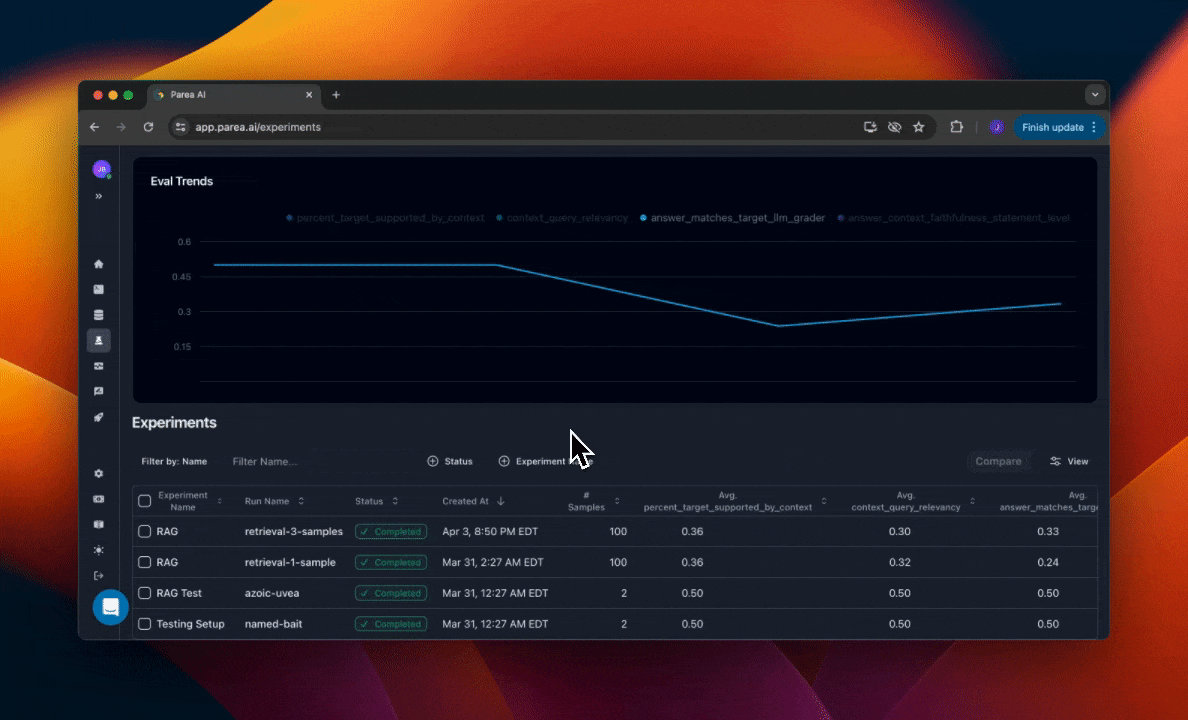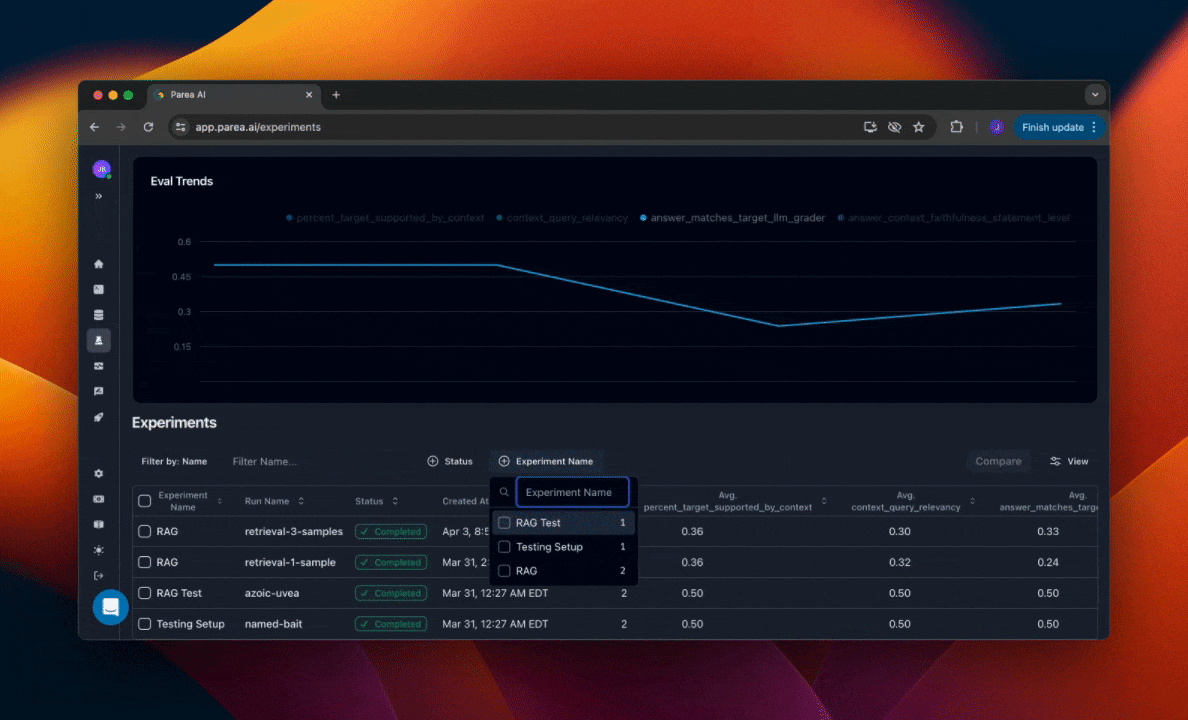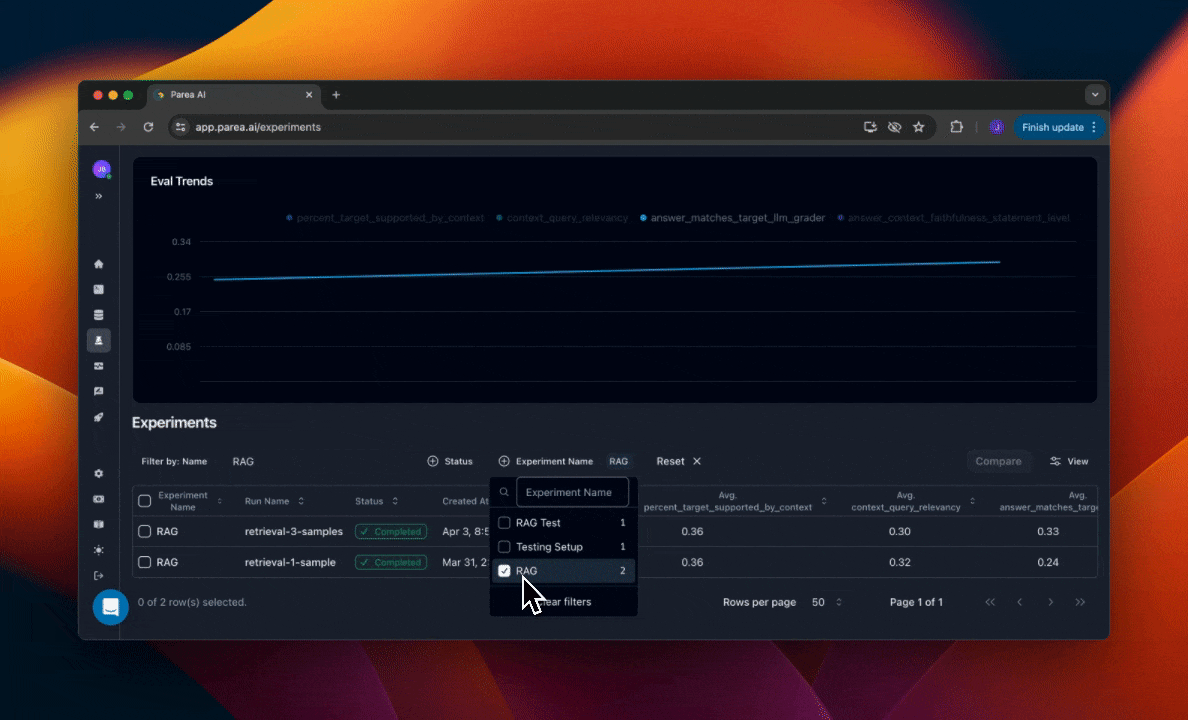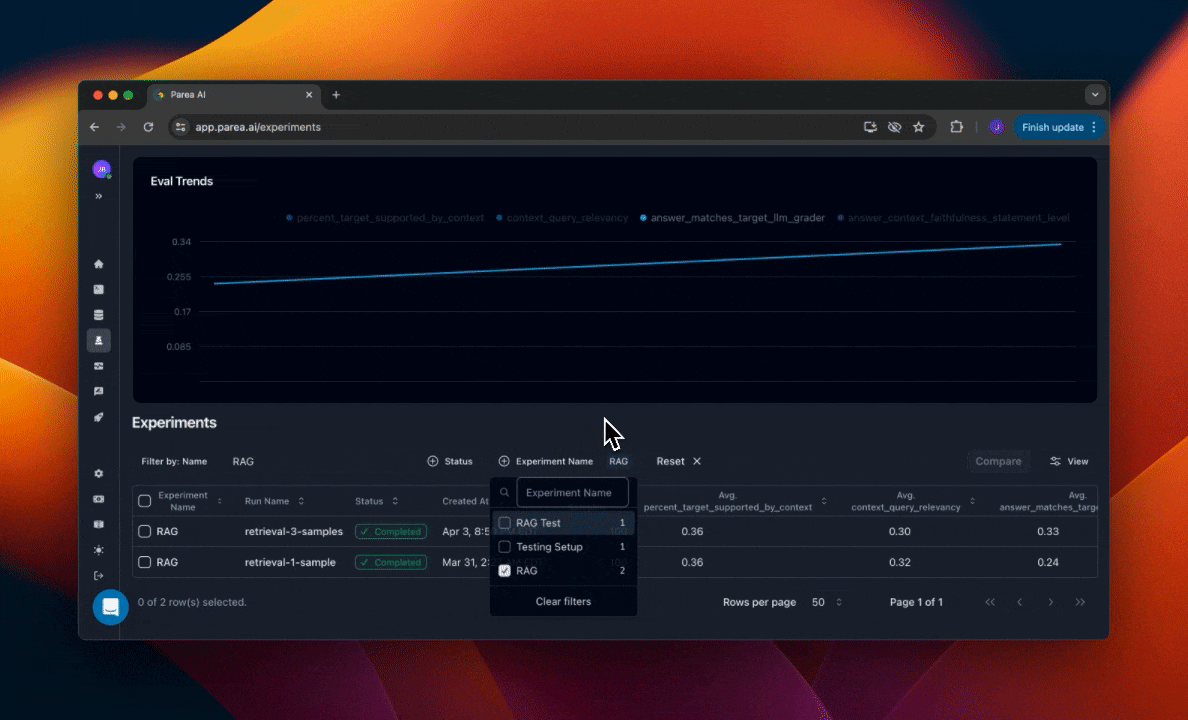
Organize Experiments by Projects
You can organize your experiments by projects. By default, all logs, traces & experiments are grouped in thedefault project.
You can specify a project name when you initialize the Parea client.
This will automatically create a new project with that name if it didn’t exist before.
Note, that the name of the project is only allowed to contain alphanumeric characters, dashes and underscores.
Testing Sub-steps
When building RAG applications, it’s useful to test the retrieval and generation steps separately to pinpoint what goes wrong. Similarly, when building agents, one typically wants to test every individual step for the expected output to catch cascading failures. You can test sub-steps via Parea by attaching thetrace decorator to the respective functions with the corresponding eval.
This will create scores from every sub-step, when running the entrypoint function (no matter if running an experiment or running the function directly).
To access different targets/expected outputs for sub-steps, you can pass the target as a dictionary when defining the experiment.
Note, that this will convert the target to a string such that you will need to convert it back to a dictionary in the evaluation function in order to access the sub-step target.
See Python & TypeScript examples below.
Example: Testing Sub-steps
Example: Testing Sub-steps
Trials
Given the non-deterministic behavior of LLMs it could be useful to run the evaluation multiple times per input to check response consistency, i.e., to run multiple trials. You can do that by specifying then_trials parameter when defining an experiment:
Debug Individual Traces
You can debug individual traces to understand how your LLM app returned an output on specific inputs. You do that by clicking on the row in the log table of the experiment. In the trace view, you can step through the trace (left sidebar), see any inputs, outputs, and metadata (middle) of the selected step, and view any metrics and scores (right side).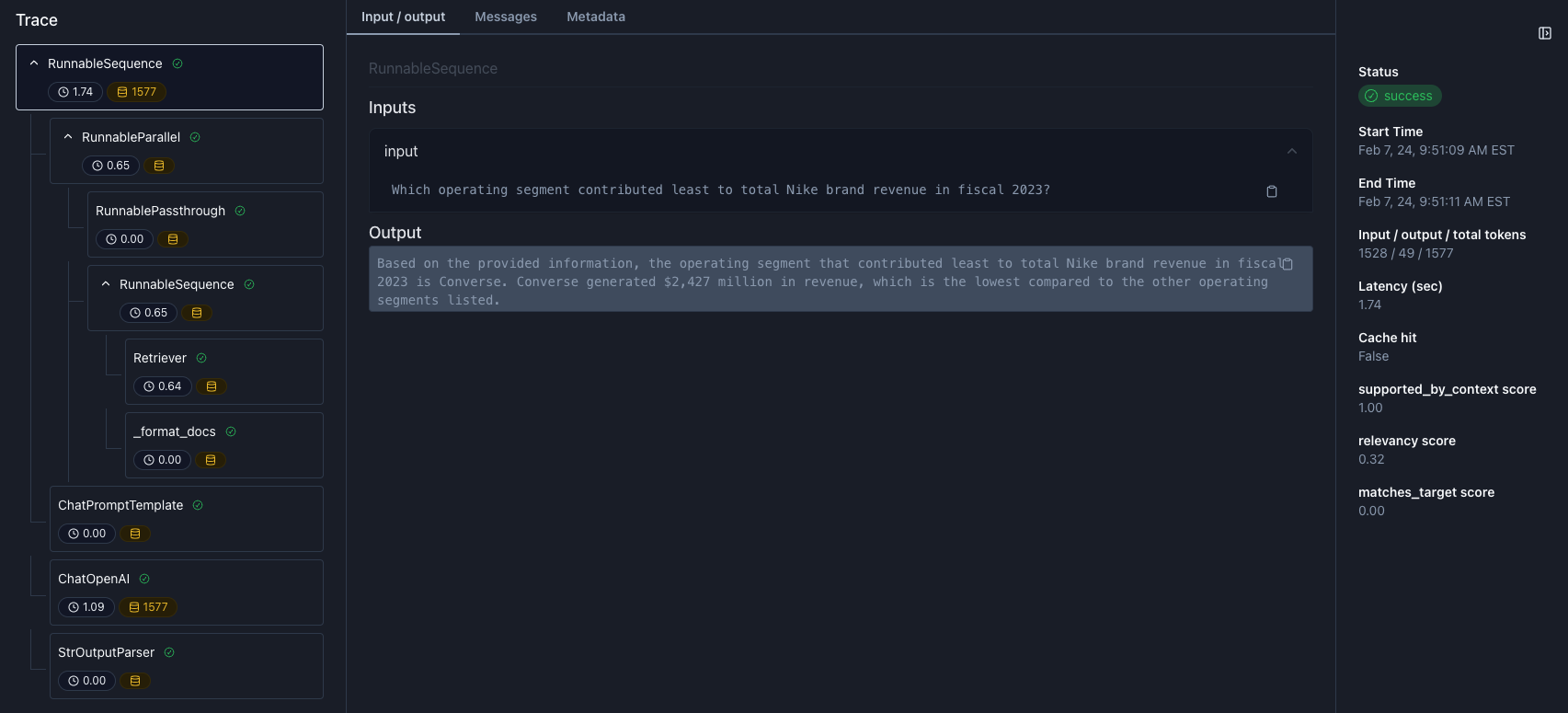
Use Saved Datasets
When running and experiment, you can use your datasets saved on Parea. For the data field just provide the name of the dataset as defined on the Datasets tab. The dataset should have column names that match the input parameters of the function you are running the experiment on. Note, the dataset name will be automatically stored in the “Dataset” key for the experiment metadata.Dataset Level Evaluation
Sometimes it’s useful to aggregate the evaluation scores over the entire dataset, e.g., for balanced accuracy. You can do that by specifying thedataset_level_evals or datasetLevelEvals parameter when defining an experiment:
EvaluatedLog objects and are expected to return a single floating point score or a boolean.
The EvaluatedLog object is a subclass of the Log object with the additional scores attribute.
The scores will be attached to the Experiment and can be viewed in the overview table and the detailed view of the experiment.
EvaluatedLog Schema Definition
EvaluatedLog Schema Definition
Dataset Level Evaluation Example (full)
Dataset Level Evaluation Example (full)
Pre-built Dataset Level Evaluations
Pre-built Dataset Level Evaluations
To simplify the process of defining dataset level evaluations, Parea provides a set of pre-built dataset level evaluations:
balanced_accuracy: The balanced accuracy of a score for the experiment; more here
Investigating Relationship Between Statistics
Sometimes it is useful to understand the relationship between different evaluation metrics, and, manual annotations. An example would be to assess how well your eval correlations / agrees with manual annotations. You can view a scatter plot of the relationship between two stats by selecting “Relationship between scores” in the dropdown above the graph in the detailed experiment view. Additionally, you can view the accuracy & correlation between the two selected variables and add that value to the experiment scores. Going back to the example of assessing how much your eval agrees with manual annotations, you can now track the quality of your eval over time and align it better with manual annotations.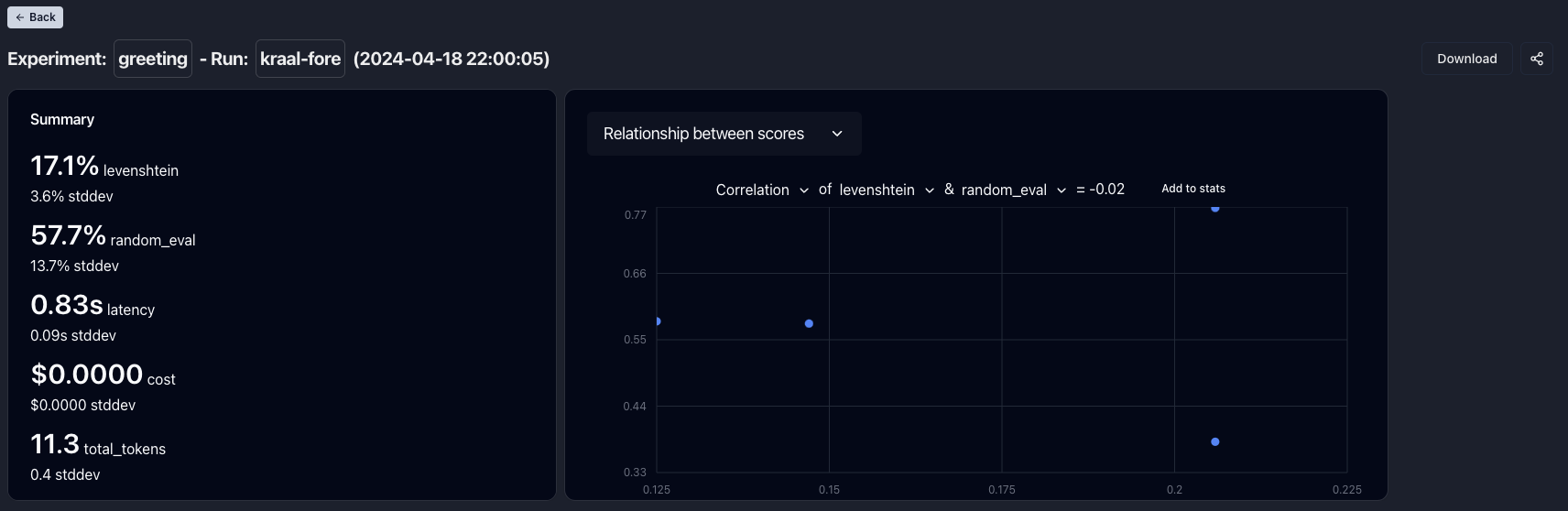
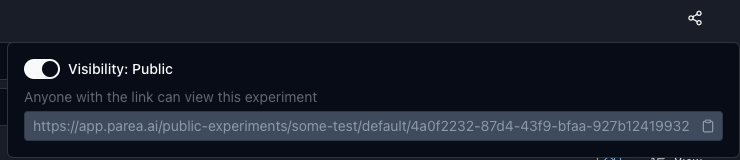
Sharing Experiments Publicly
All your experiments are shared by default in your organization and not publicly accessible. You can share experiments publicly by clicking on theShare button on the top right of the experiment page. This
will generate a link following the format
https://app.parea.ai/public-experiments/<org_slug>/<project_name>/<experiment_uuid> which anyone can access.
You can compare all public experiments in a project under https://app.parea.ai/public-experiments/<org_slug>/<project_name>.
Experiment Code Management
As you iterate on your LLM app and test the changes, keeping track of which change led to which result is cumbersome. For that Parea provides an integration with DVC’s experiment tracking. This enables you to iterate on your LLM app without polluting your git history with a commit for every experiment and still have the ability to revert your code to the state of any experiment. Once integrated, every time you run an experiment, the state of the workspace together with the associated metrics will be automatically captured. This will enable you to compare experiment metrics and to revert your workspace to the state of them.This is currently only supported for Python. Please, reach out if you want that functionality for TypeScript.
Integrating Parea with DVC
Integrating Parea with DVC
1
Setup DVC
Install DVC and initialize it via
2
Integrate Parea with DVC
Run the following command to integrate Parea with DVC and commit any files to git which the command creates:This command will check if DVC is installed as well as create a
.parea directory with a dvc.yaml and a metrics.json file if they don’t exist.
The dvc.yaml file will point to the metrics.json file and the metrics.json file will contain the metrics of the experiments.
Both files are necessary for DVC. You can always re-run the command to check if the integration is set up properly.
dvc exp show here, and dvc exp apply here.
Add Metadata to Experiments
When running an experiment, you can add metadata to the experiment by passing a dictionary. These metadata will be displayed on the experiment overview table and can be used to filter and search for experiments.
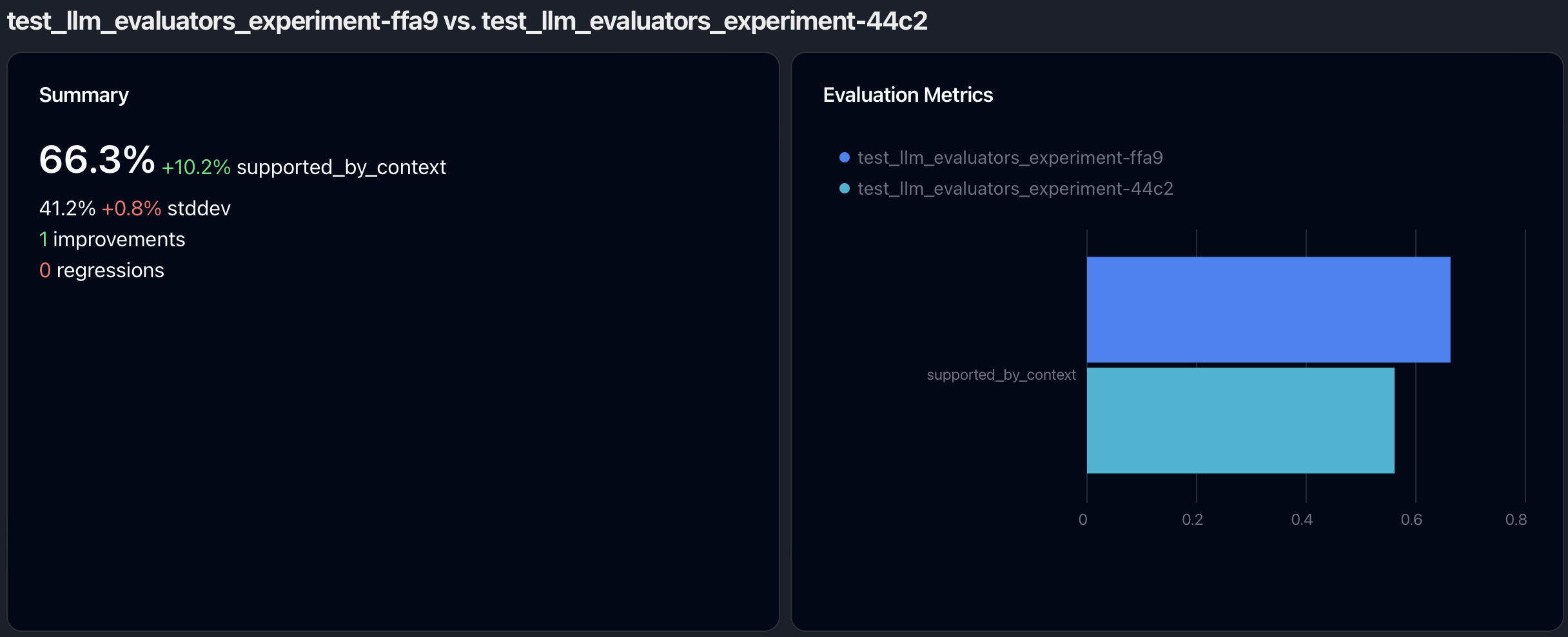
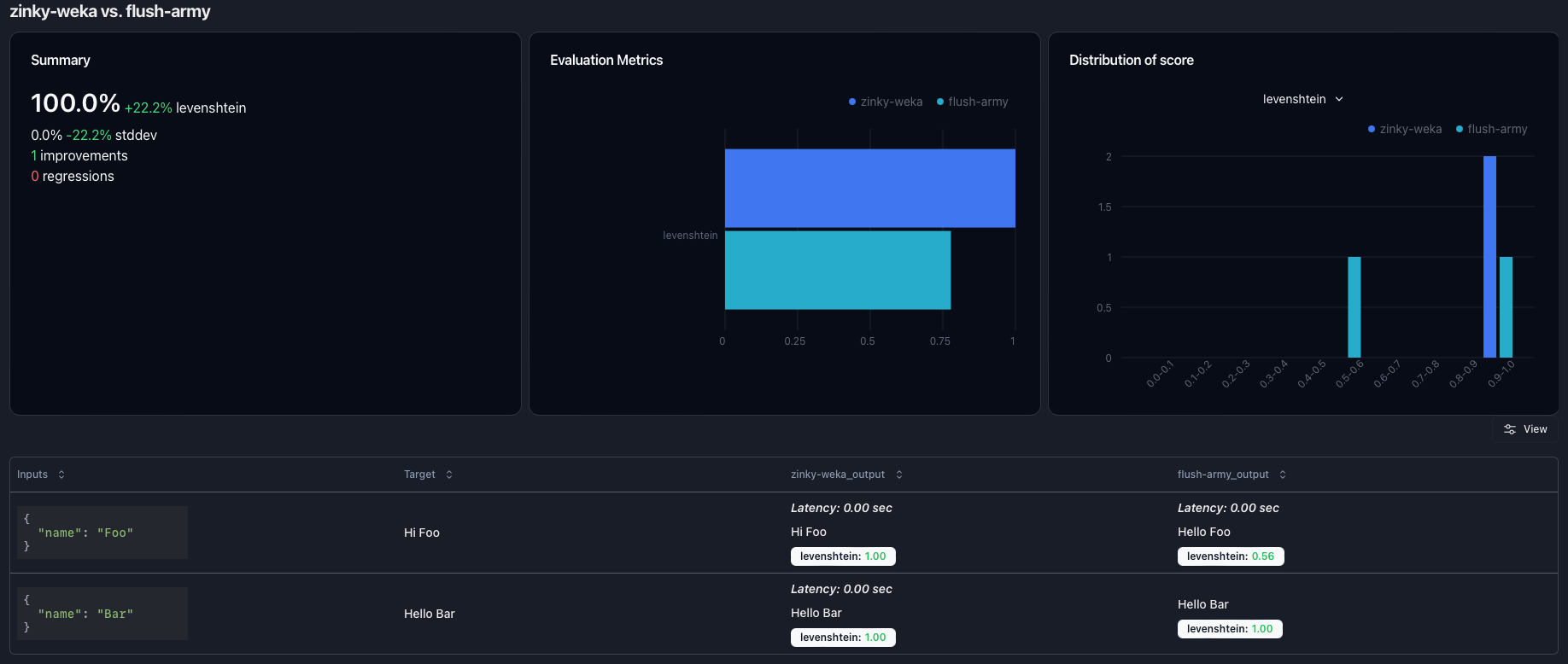
Comparing Experiments
You can select 2 or more experiments in the experiment overview section and click on theCompare button to compare them.
This will open up a new view which shows
a high-level comparison of the experiment scores at the top and
a side-by-side view of the individual results of the experiments on the same samples at the bottom.
The high-level comparison consists of 2-3 cards.
The first card is only shown if 2 experiments are compared,
and it displays for every evaluation metric how average and standard deviation have changed as well as the number of improvements and regressions.
The second card compares the evaluation metric averages for every experiment as a bar plot.
The third card shows the distribution plot of the selected evaluation metric as a histogram.
Controlling Parallelism
You can specify on how many samples your experiment should be executed in parallel by setting then_workers / nWorkers parameter when defining an experiment.
Integrate into CI/CD
After creating an experiment and evaluating your LLM app, you can integrate the experiment into your CI/CD pipeline as a test.Running Experiments in Jupyter Notebooks
In order to execute experiments in a Jupyter notebook, you will need to installnest-asyncio and apply it: