Sample app: email generation
In our currently existing version of an email generator we instruct the LLM to generate long emails. With our A/B test, we will assess the effect of changing the prompt to generate short emails.Original email generation code
Original email generation code
To instrument our application, we use
wrap_openai_client/patchOpenai to automatically trace any LLM calls made by the OpenAI client, and trace to capture the inputs and outputs of the generate_email function.Route requests randomly to the variants
In our A/B test we will test the effect of changing the prompt to generate short emails instead of long emails. To execute the A/B test, calledlong-vs-short-emails, we will randomly choose to generate a long email (variant_0, control group) or a short email (variant_1, treatment group).
Then, we will tag the trace with the A/B test name and the chosen variant via trace_insert.
Finally, we will return the email, the trace_id, and the chosen variant.
We need to return the latter two in order to associate any feedback with the corresponding variant.
Capture the feedback
Now that different requests are routed to different variants, we need to capture the associated feedback. Such feedback could be if the email got a reply or lead to booking a meeting (e.g. in the case of sales automation) or if the user gave a thumbs up or thumbs down (e.g. in the case of an email assistant). To do that, we will use the low-levelupdate_log function of parea_logger to update the trace with the collected feedback as a score.
Analyzing the results
Once, the A/B test is live, we can check the results in the dashboard by filtering the logs for metadata keyab_test_name being long-vs-short-emails.
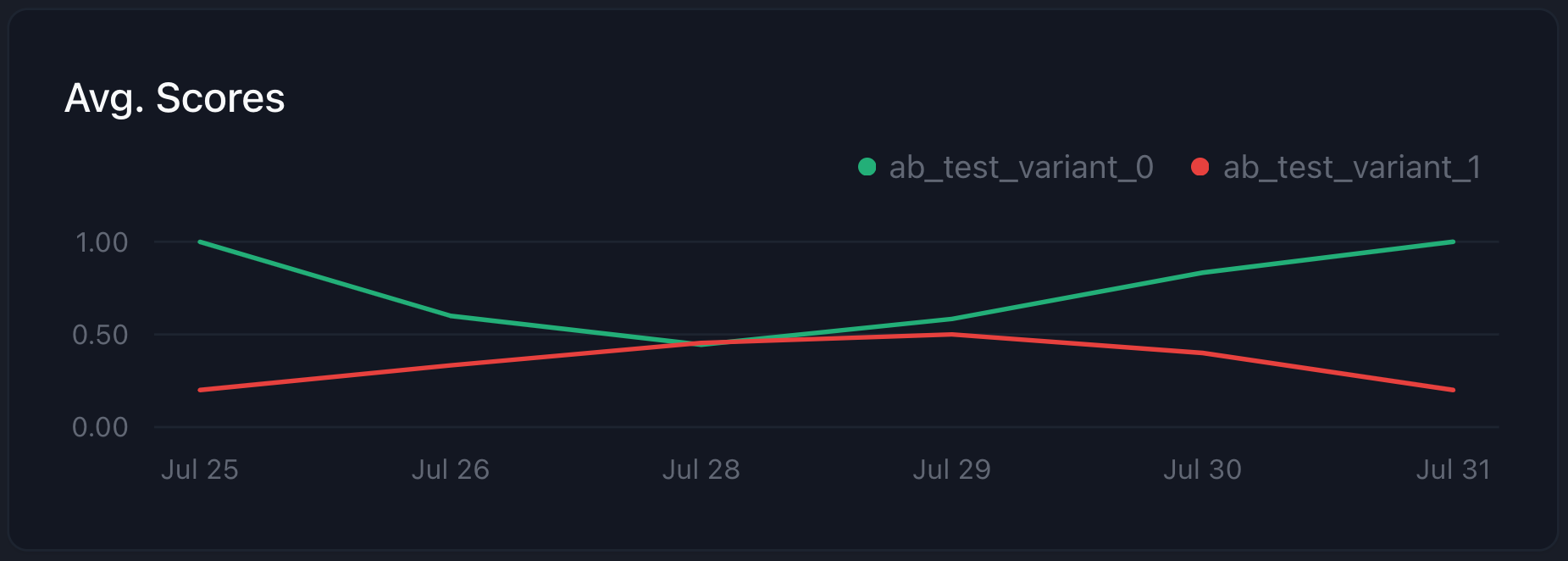
variant_1 (short emails) performs a lot better than variant_0 (long emails)!
Checkout the full code below for why this variant is performing better.
Note, despite the clearly higher score, never forget to LOOK AT YOUR LOGS to understand what’s happening!
Bonus: capture user corrections
If your application is interactive and enables the user to correct the generated email, you should capture the correction and add it to a dataset. This dataset of user corrected emails will be very useful for any future evals of your LLM app as well as opens the door to fine-tuning your own models. You can capture the correction in Parea by sending it astarget in the update_log function:
target field.
After reviewing it, you can add it to a dataset by clicking on the Add to dataset button or pressing Cmd + D.
Conclusion
In this cookbook, we demonstrated how to run A/B tests to optimize your LLM app based on user feedback. To recap, you need to route requests to the variants you want to test, capture the associated feedback, and analyze the results in the dashboard. If you are able to capture corrections from your users, it is strongly recommended to add them to a dataset for future evaluation.Full Code
Full Code
Below you can see the full working code for the A/B test.
You also can find them in our Python and TypeScript SDK cookbooks.