Inputs: prompt variable values that are interpolated into the prompt template of your model config at generation time (i.e., they replace the{{ variables }}you define in the prompt template.Target: Represents the expected or intended output of the model.Tags: Any string metadata tags you want to attach to a test case.
Creating Datasets
From uploaded CSV
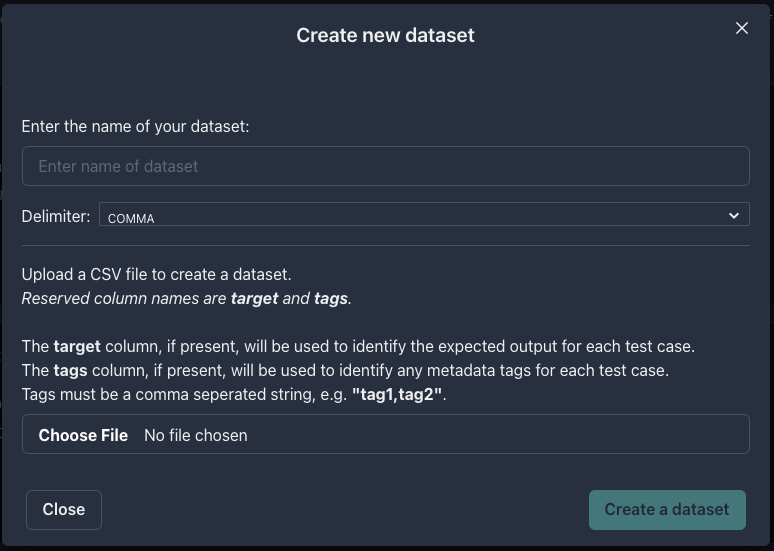
You can create a dataset by uploading a CSV file to the Datasets tab. Go to Datasets tab and clickUpload file to create dataset. In the following modal, provide a name for your
dataset and upload your file.
prompt template
question.
Different delimiter types are supported, including comma, tab, pipe, and semicolon.
target and tags are reserved.
If a target column is present, it will be used as the gold standard answer for that row’s output.
For example, in the CSV below, the target 4 is the expected answer to the question What is 2 + 2.
CSV
tags column is present, it will be used as metadata tags for a specific row. Tags should be comma-separated with no spaces.
For example, in the CSV below, row one has been tagged as easy and arithmetic, and the second row hard and calculus.
CSV
From the SDK
Using the Python or TypeScript SDK, you can create, read and update datasets programmatically. See the api-reference for more details.From the playground
In the playground, after you clickAdd test case, you can optionally select Upload new dataset to upload a CSV file.
From trace logs
See Observability - Datasets for more details.From annotation queues
See labeling in annotation queues for more details.Exporting Datasets
You can use the Python or TypeScript SDK to export datasets via the Get Dataset endpoint (API docs).Converting to JSONL for fine-tuning
You can use helper functions in the SDK to download and then convert a dataset to JSONL format for fine-tuning.Sample Output File
Sample Output File