Overview
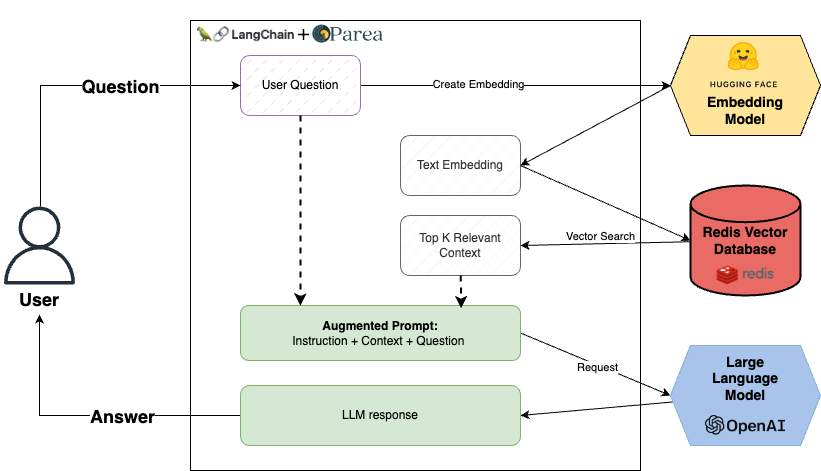
We will start with the Redis-Rag example from Langchain and instrument it with Parea AI. This application lets users chat with public financial PDF documents such as Nike’s 10k filings.
Application components:
- UnstructuredFileLoader to parse the PDF documents into raw text
- RecursiveCharacterTextSplitter to split the text into smaller chunks
all-MiniLM-L6-v2sentence transformer from HuggingFace to embed text chunks into vectors- Redis as the vector database for real-time context retrieval
- Langchain OpenAI
gpt-3.5-turbo-16kto generate answers to user queries - Parea AI for Trace logs, Evaluations, and Playground to iterate on our prompt
Getting Started
First, clone the project repo here. Follow the Readme to set up your environment variables. Ensure you have the Redis stack server installed, then start a local Redis instance withredis-stack-server.
Then, install the dependencies with poetry install.
Ingest Documents
Now that our application is ready, we must first ingest our Nike 10k source data. To make this easier, the repo has a helper CLI. You can run the below command in your terminal.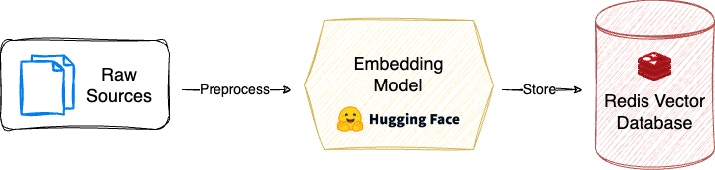
Execute the RAG Chain
Now that the docs are loaded, we can run our RAG chain. Let’s see if our RAG application can understand the Operating Segments table on page 36 of the 10-k.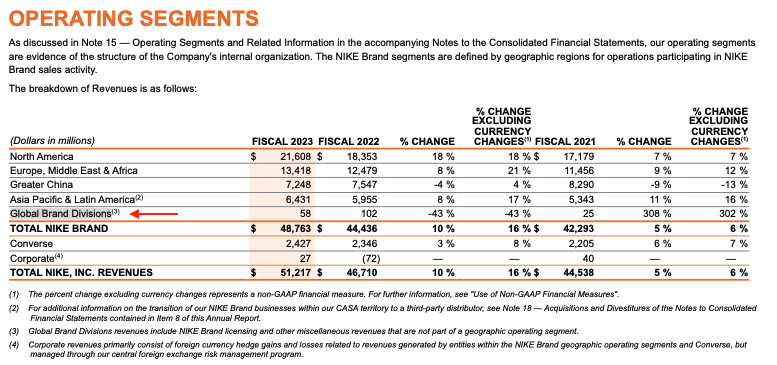
- Relevancy quantifies how much the retrieved context relates to the user question.
- Supported by context quantifies how many sentences in the target answer are supported by the retrieved context.
Which operating segment contributed least to total Nike brand revenue in fiscal 2023?.
The PDF document shows that the correct answer should be Global Brand Divisions, which contributed the least to total brand revenue, with $58M in F2023.
To run our chain, we can use the CLI command to execute the chain with the default question above:
Converse, which is not correct. Notice that we also fail our matches target eval with a score of 0.0.
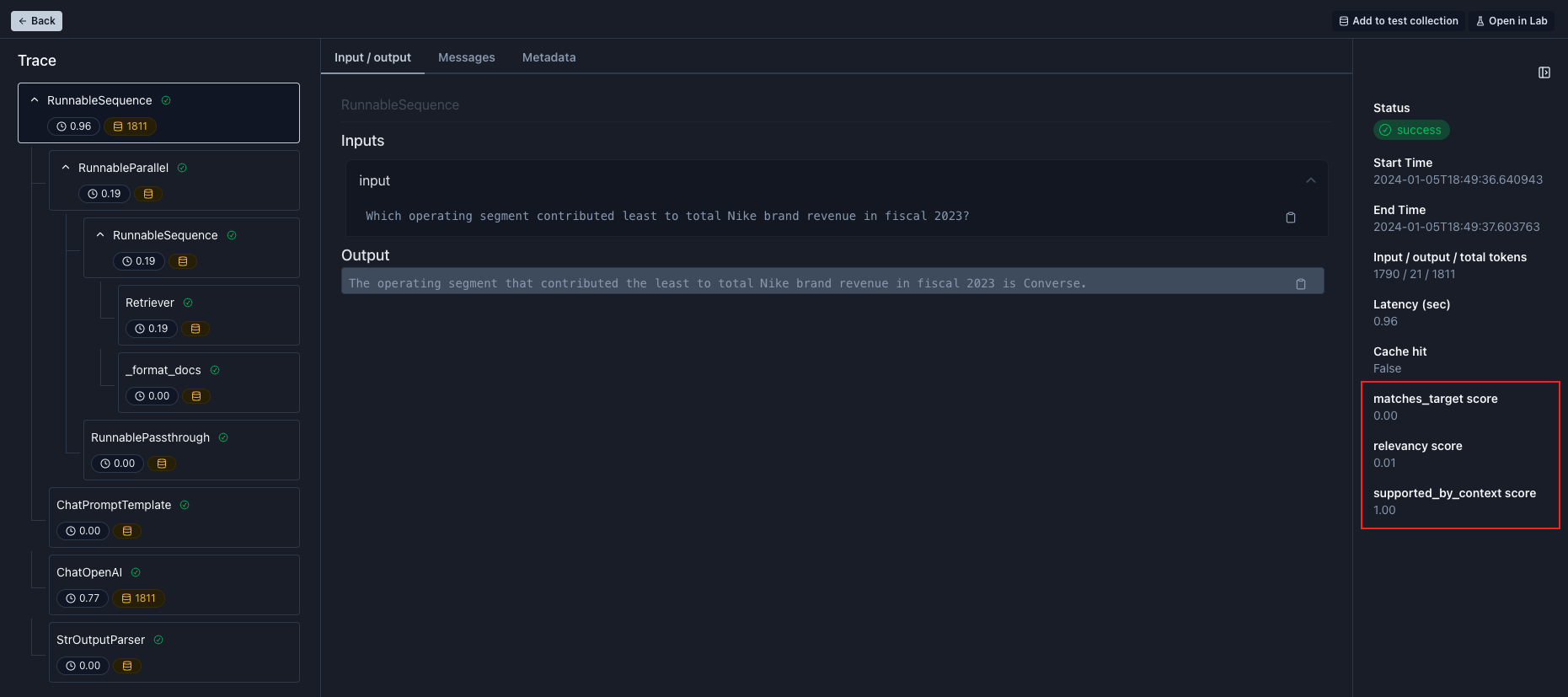
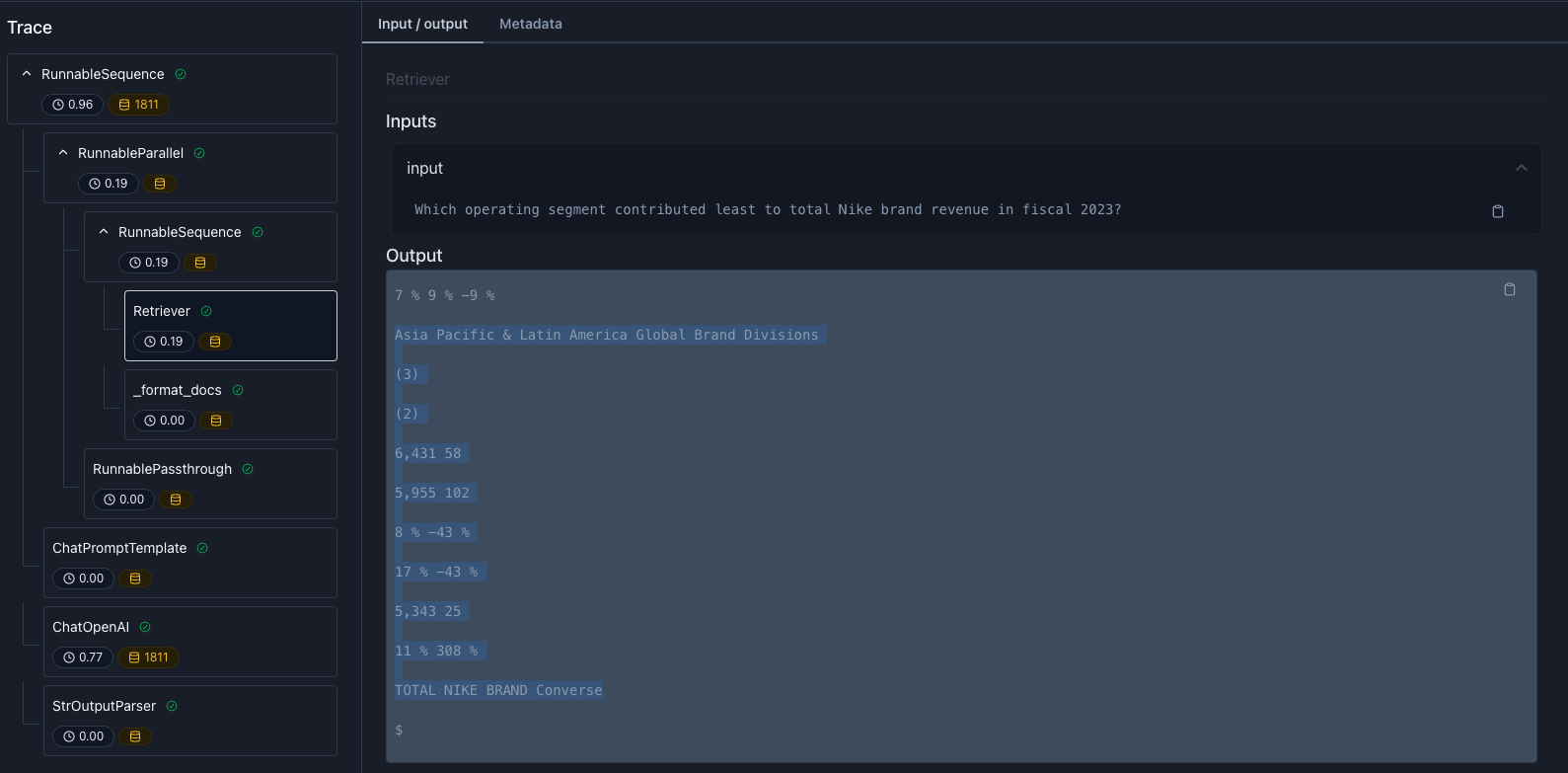
- Table parsing is likely hard to interpret, and
- the segment
Conversecomes right after the subtotalTOTAL NIKE BRANDfollowed by a trailing dollar sign ($)
Prompt Engineering to improve results
Add to test collection
To experiment with our prompt and context, we can add this example to a dataset by clicking theAdd to test collection button in the top right.
Later, we can use this test case to iterate on our prompt in the playground.
The Add to test collection modal is very flexible; it pulls in the inputs, output, and tags from our selected trace and allows us to edit the information as needed.
- First, we’ll click the
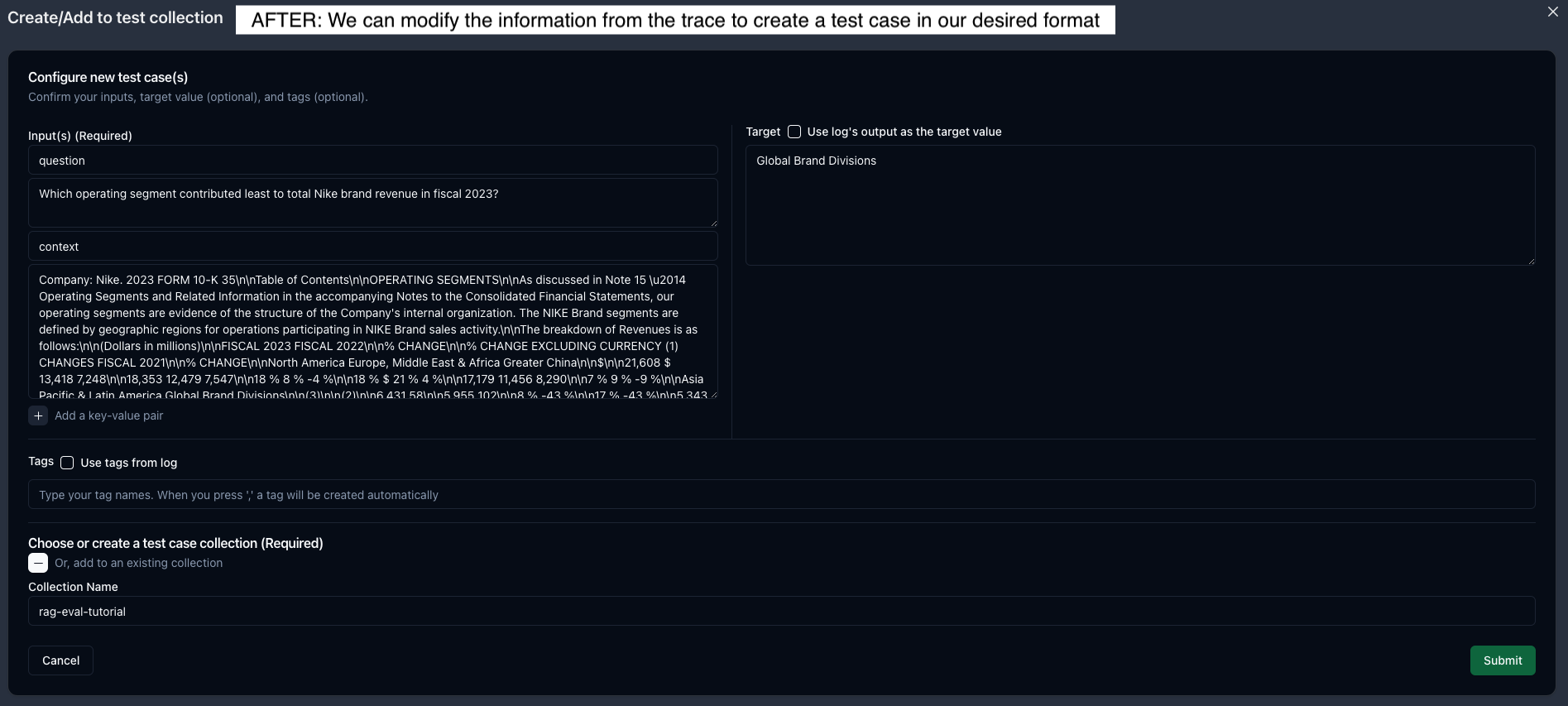
RunnableParalleltrace, then clickAdd to test collection.This trace is helpful because it has both our input question and the retrieved context. - Second, let’s change the name from
inputtoquestionand add a new k/v pair for thecontext,using the original output value. - Third, we can set our target answer to
Global Brand Divisions. - Finally, we’ll click the
+to create a new test collection by providing a name and then submitting.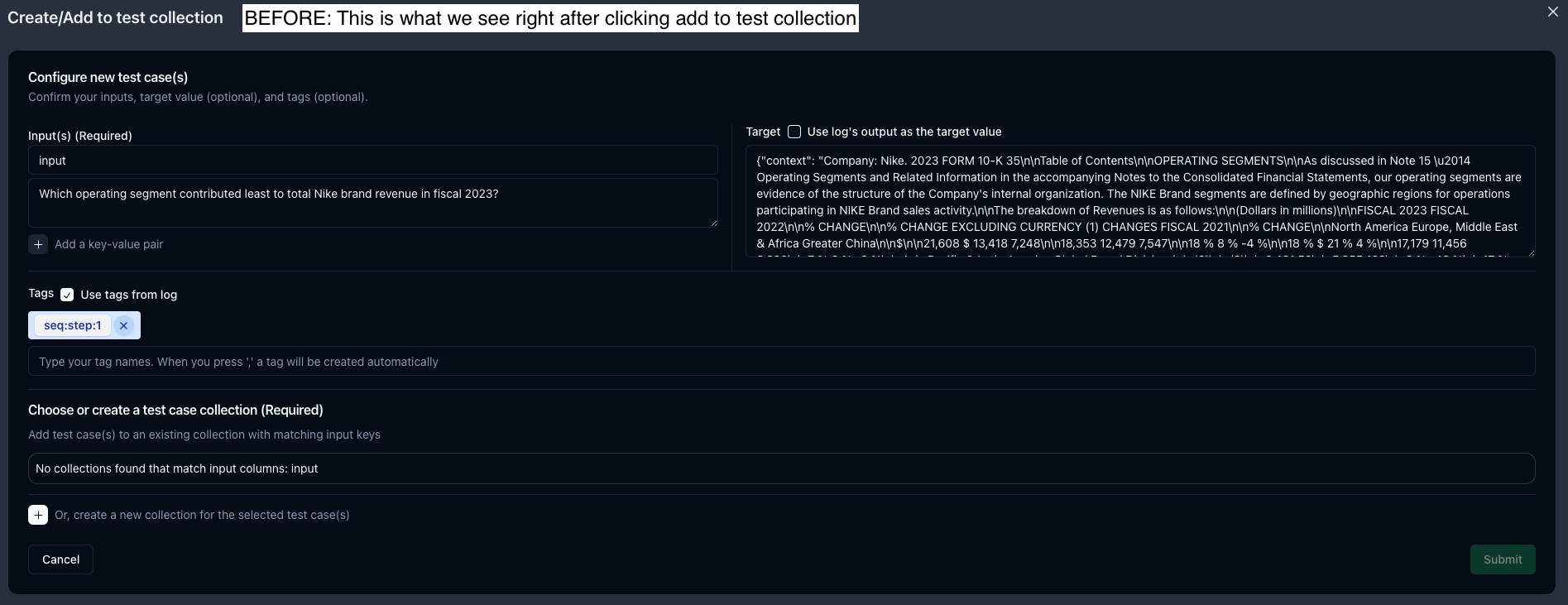
Evaluations - Create an eval metric
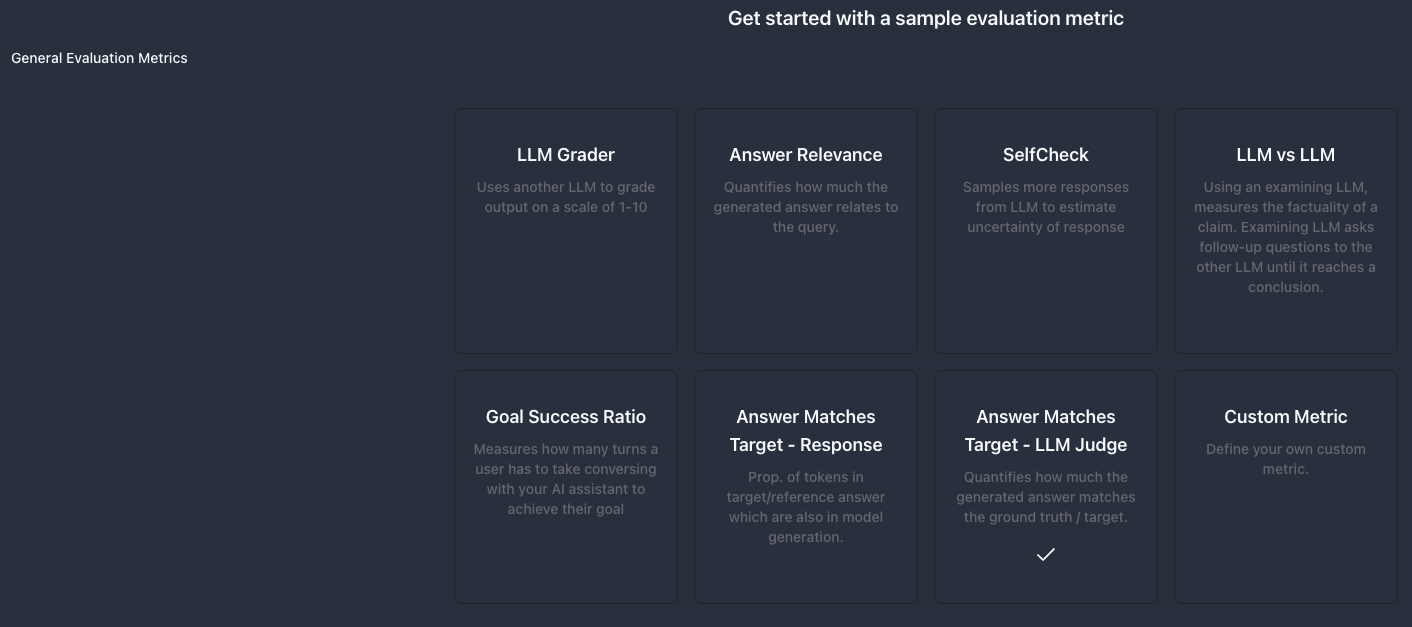
All of Parea’s AutoEvals are also available in the app. Go to the Evaluations and choosecreate function eval. We’ll only select the match target eval for demo purposes. Under the General Evaluation Metrics section, select Answer Matches Target - LLM Judge.
No changes are needed because we named our input field question. in the test collection setup, so we can click create metric and then proceed to the Playground.
Playground
Since our prompt is simple, we can go to the Playground and click create a new session. An alternative would be to revisit our trace log and clickOpen in Lab on the ChatOpenAI trace, which includes the LLM messages.
- First, paste in our Chat template from here and format it to use double curly braces (
{{}}) for template variablesquestionandcontext,and select thegpt-3.5-turbo-16kmodel.
Prompt
- Second, click
Add test caseand import our created test case. - Third, click
Evaluation metricsand select the new eval we created. - Now, we are ready to iterate on our prompt to improve the result. If we do not change the prompt and click
Compare,we will see the same response as in our IDE.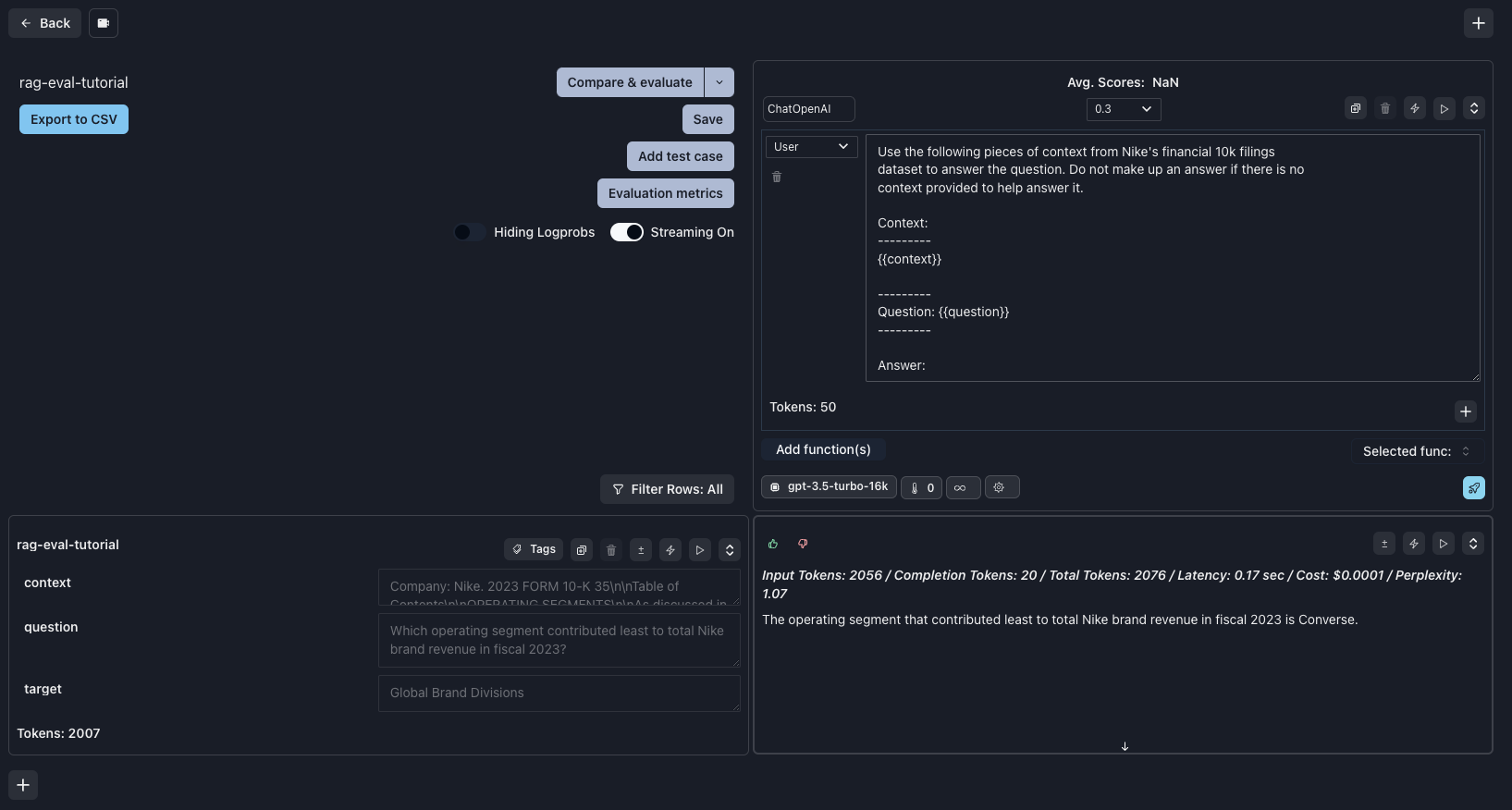
Prompt Iteration
At first, I considered adding additional information to the prompt, clarifying that the context is financial data with tables. However, this prompt must be generalizable to user questions that don’t retrieve tables. So, instead, let’s try the tried-and-trueChain of Thought prompt: Think step by step. We can add this as our initial user message.
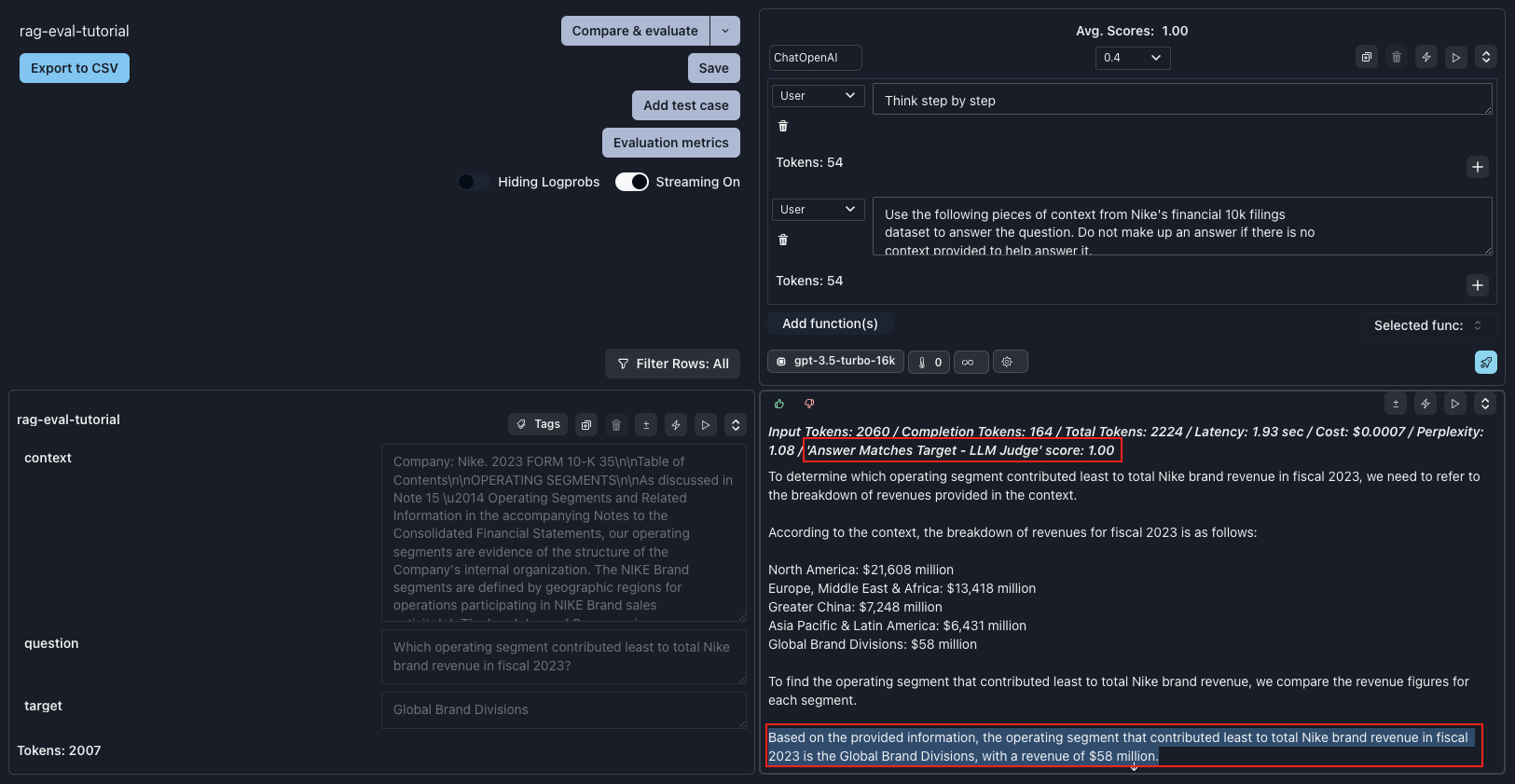
1.0.
🎉Congratulations, it works!🎉 Now, we can copy this prompt back into our application and continue building.