Prerequisites
- First, you’ll need a Parea API key. See Authentication to get started.
- For any model you want to use with the SDK, set up your Provider API keys.
- Install the Parea SDK.
Logging
Parea automatically logs all LLM requests when using the SDK, or when using OpenAI’s API.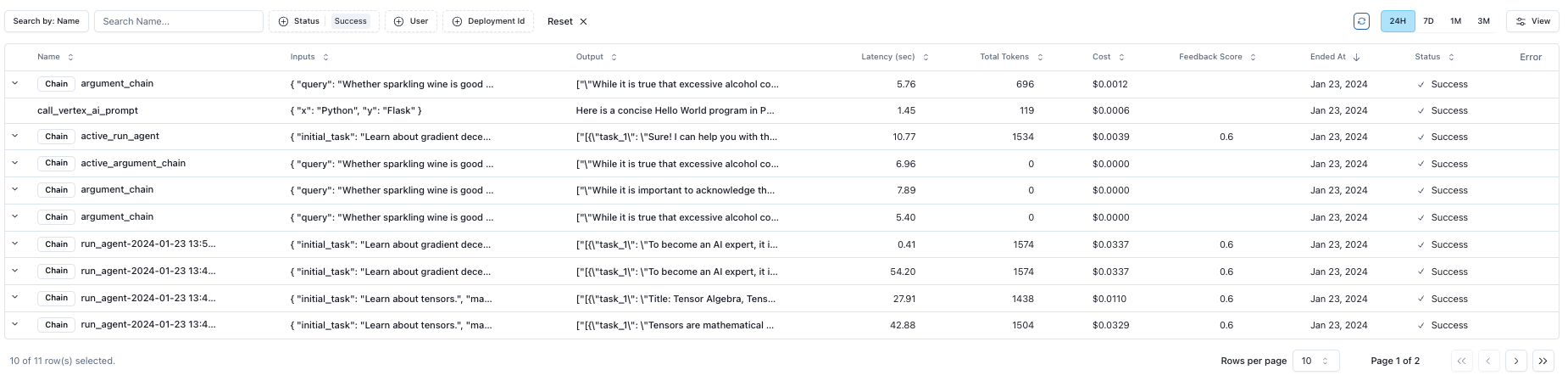
Usage
- Python
- Typescript
- Curl
Parea supports automatic logging for OpenAI, Anthropic, Langchain, or any model if using Parea’s completion method (schema definition).
OpenAI API
If you want to use OpenAI directly, you can still get automatic logging using Parea’swrap_openai_client helper.openai.py
Anthropic API
If you want to use Anthropic’s Claude directly, you can still get automatic logging using Parea’swrap_anthropic_client helper.anthropic.py
Parea Completion Method
The completion method allows you to call any LLM model you have access to on Parea with the same API interface.You have granular control over what is logged via the parameters on Parea’s completion method.log_omit_inputs: bool = field(default=False) # omit the inputs to the LLM calllog_omit_outputs: bool = field(default=False) # omit the outputs from the LLM calllog_omit: bool = field(default=False) # do not log anything
parea_completion.py
LangChain Framework
Parea also supports frameworks such as Langchain. You can usePareaAILangchainTracer as a callback to automatically log all requests and responses.langchain.py
Tracing
If your LLM application has complex abstractions such as chains, agents, retrieval, tool usage, or external functions that modify or connect prompts, then you will want a trace to associate all your related logs. A Trace captures the entire lifecycle of a request and consists of one or more spans, representing different sub-steps.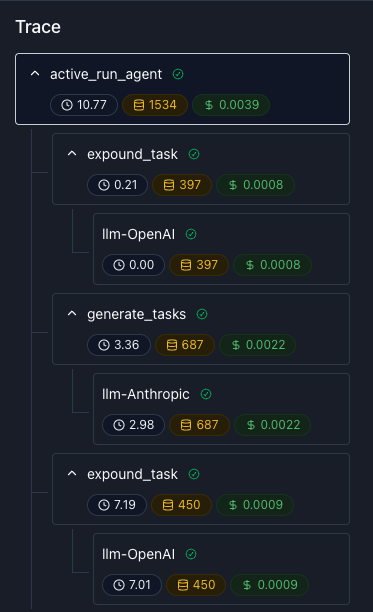
Usage
- Python
- Typescript
- Curl
The
@trace decorator allows you to associate multiple processes into a single parent trace.
You only need to add the decorator to the top level function or any non-llm call function that you want to also track.OpenAI API
If you want to use OpenAI directly, you can still get automatic logging using Parea’swrap_openai_client helper.openai_trace_decorator.py
Parea Completion Method
trace_decorator.py
Limitations
Python: Threading & Multi-processing
Thetrace decorator relies on Python’s contextvars to create traces.
However, when spawning threads from inside a trace the decorator will not work correctly as the contextvars are not correctly copied to the new threads or processes.
There is an existing issue in Python’s standard library and a great explanation in the FastAPI repo that discusses this limitation.
For example when a @trace-decorated function uses a ThreadPoolExecutor to make concurrent LLM requests the context that holds important info on the nesting hierarchy (“we are inside another trace”) is not copied over correctly to the child threads.
So, the created generations will not be linked to the trace and be ‘orphaned’.
In the UI, you will see a trace missing those generations.
A workaround is to manually copy over the context to the new threads or processes via contextvars.copy_context.
This is the recommended approach when using threading or multi-processing in Python.
Disabling/sampling logging
You can either disable logging or only store a percentage of all logs in Parea.- Python
- TypeScript
- Curl
In Python, you can disable logging by setting the environment variable
TURN_OFF_PAREA_LOGGING to True.
Alternatively, you can also deactivate logging by using the parea.helpers.TurnOffPareaLogging context manager.
In order to reduce the amount of logs stored in Parea, you can specify the log_sample_rate in the trace decorator or completion function