TURN_OFF_PAREA_EVAL_LOGGING to True.
- Using evaluation functions from your code base
- Using evaluation functions created on the platform
Using evaluation functions from your code base
You can define evaluations functions locally in your codebase. The evaluation is required to receive aLog object and return a float or boolean value.
The evaluation function will be executed non-blocking in a separate thread and the results will be logged.
An example implementation is shown below:
Using Pre-built SOTA evaluation functions
Parea provides a set of state-of-the-art evaluation metrics you can plug into your evaluation process. Their motivation & research are discussed in the blog post on reference-free and reference-based evaluation metrics. Here is an overview of them:General Purpose Evaluation
General Purpose Evaluation
levenshtein: calculates the number of character-edits in the generated output to match the target and normalizes it by the length of the output; more herellm_grader: leverages a general-purpose zero-shot prompt to rate responses from an LLM to a given question on a scale from 1-10; more hereanswer_relevancy: measures how relevant the generated response is to the given question; more hereself_check: measures how well the LLM call is self consistent when generating multiple responses; more herelm_vs_lm_factuality: uses another LLM to examine original LLM response for factuality; more heresemantic_similarity: calculates the cosine similarity between output and ground truth; more here
RAG Specific Evaluations
RAG Specific Evaluations
context_query_relevancy: calculates the percentage of sentences in the context are relevant to the query; more herecontext_ranking_pointwise: measures how well the retrieved contexts are ranked by relevancy to the given query by pointwise estimation; more herecontext_ranking_listwise: measures how well the retrieved contexts are ranked by relevancy to the given query by listwise estimation; more herecontext_has_answer: classifies if the retrieved context contains the answer to the query; more hereanswer_context_faithfulness_binary: classifies if the answer is faithful to the context; more hereanswer_context_faithfulness_precision: calculates how many tokens in the generated answer are also present in the retrieved context; more hereanswer_context_faithfulness_statement_level: calculates the percentage of statements from the generated answer that can be inferred from the context; more here
Chatbot Specific Evaluations
Chatbot Specific Evaluations
goal_success_ratio: measures how many turns a user has to converse on average with your AI assistant to achieve a goal; more here
Summarization Specific Evaluations
Summarization Specific Evaluations
factual_inconsistency_binary: classifies if a summary is factually inconsistent with the original text; more herefactual_inconsistency_scale: grades the factual consistency of a summary with the article on a scale from 1 to 10; more herelikert_scale: grades the quality of a summary on a Likert scale from 1-5 along the dimensions of relevance, consistency, fluency, and coherence; more here
parea.evals module
and attaching them to the trace decorator.
Using evaluation functions created on the platform
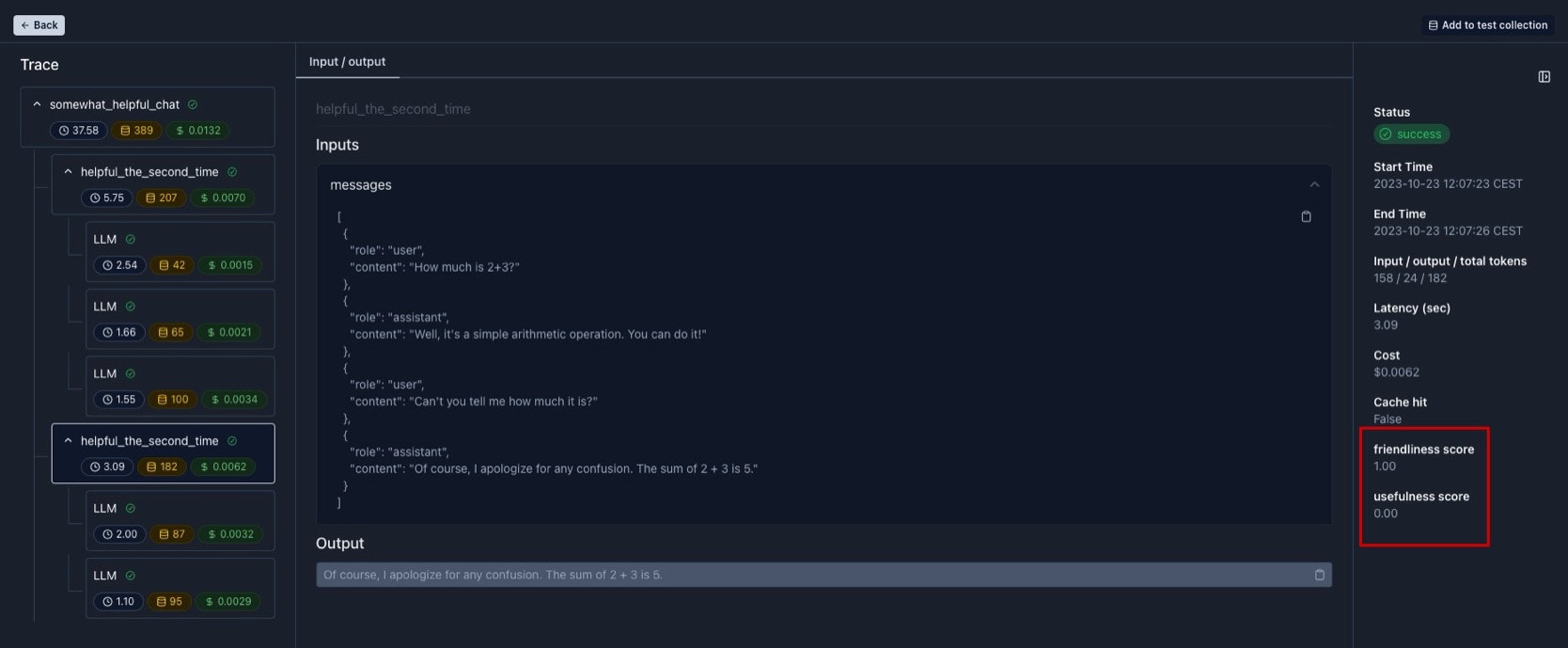
After creating an evaluation function on the platform, you can use it to automatically track the performance of the components of your LLM app. For that, simply wrap the function you want to track with thetrace decorator and the evaluation function will be executed in the backend in a non-blocking way:
Run Evaluations on sample of logs
You can also limit how many logs you run evaluations on by setting a sampling rate using theapply_eval_frac
or applyEvalFrac argument for Python and Typescript, respectively. This is useful if you want to reduce the cost of evaluating.