PareaAILangchainTracer you can automatically subscribe to all exposed LangChain events.
Quickstart
Add thePareaAILangchainTracer as a callback when running your Langchain model/chain/agent:
Parea and the PareaAILangchainTracer. Follow these steps to get an API key.
Where to set callbacks
There are two ways callbacks can be passed - as constructor callbacks and as request callbacks.- Constructor callbacks are defined in the constructor of an object and apply to all calls made on that specific object. The scope is limited to the object itself.
- Request callbacks are defined in the run() or apply() methods used for sending a request. They are applied to a specific request and all sub-requests it contains. For example, passing a handler to the chain.run() method will be used for that particular request and any subsequent sub-requests triggered. Additional details here.
Visualizing your traces
Every time you run a LangChain component with tracing, the call hierarchy for the run is saved and can be visualized in the app on the Logs tab. You can drill down into the components inputs and outputs, parameters, response time, token usage, and other important metadata.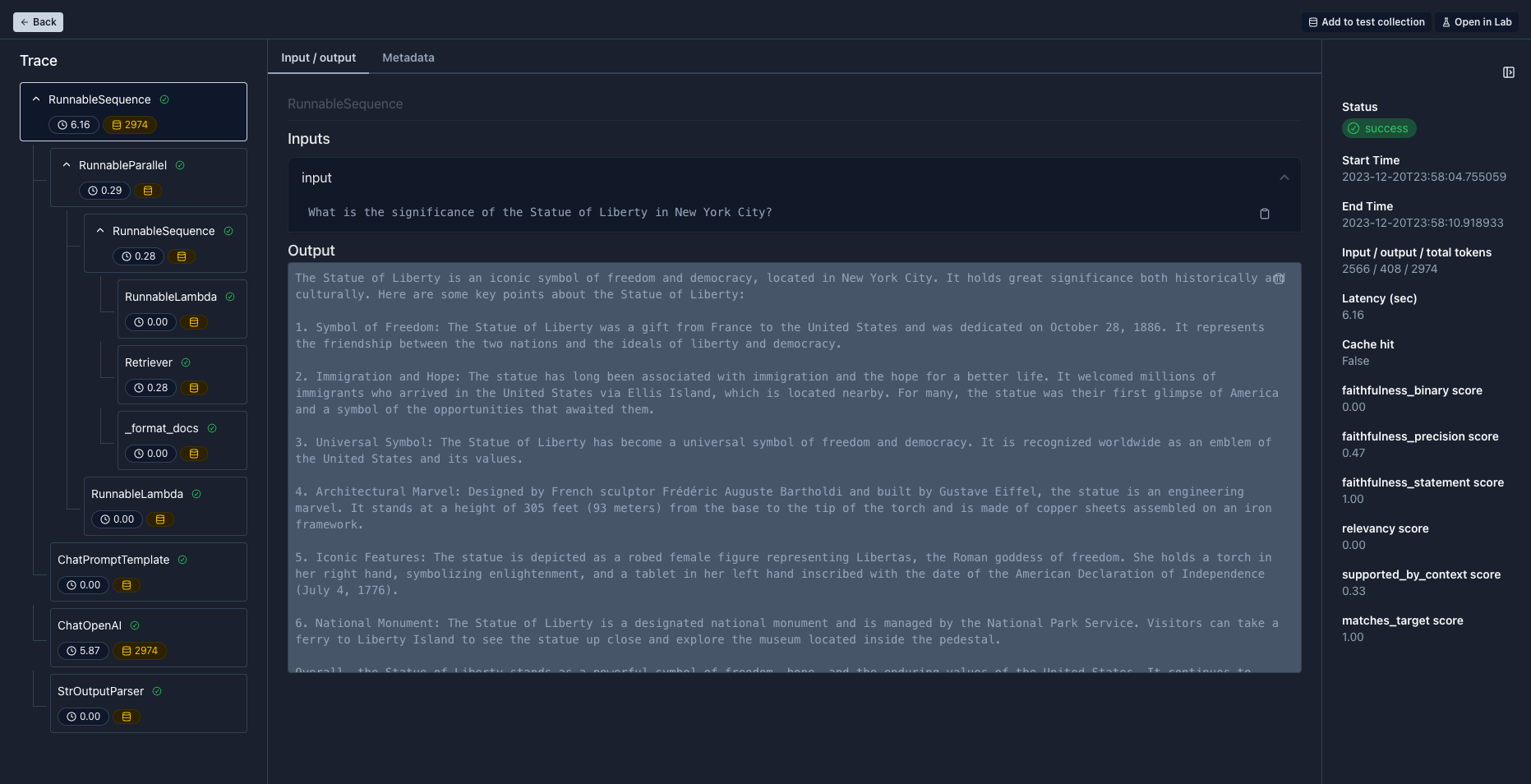
Evaluating a Langchain RAG application
Below is an example of how to use thePareaAILangchainTracer and Langchain to evaluate a RAG chain. The code can be found in the cookbook here.
Python
Tracing LangChain code together with other code
If you want to observe or test LangChain code and other code together, thetrace decorator plays well with that and will associate any traces, LLM calls, and LangChain logs.
You can see a schematic example below:
langchain_inside_trace.py
Full working example
Full working example
langchain_inside_trace.py