wrap_openai_client/patchOpenAI methods.
Quickstart
Assuming you had a liteLLM config.yaml file with the following content:model_list:
- model_name: gpt-4o # user-facing model alias
litellm_params: # all params accepted by litellm.completion() - https://docs.litellm.ai/docs/completion/input
model: gpt-4o
api_key: OPENAI_API_KEY
- model_name: claude-3-haiku-20240307 # user-facing model alias
litellm_params:
model: claude-3-haiku-20240307
api_key: ANTHROPIC_API_KEY
- model_name: azure_gpt-3.5-turbo
litellm_params:
model: azure/<azure_model_name>
api_key: AZURE_API_KEY
api_base: https://<url>.openai.azure.com/
- model_name: anthropic.claude-3-haiku-20240307-v1:0
litellm_params:
model: bedrock/anthropic.claude-3-haiku-20240307-v1:0
aws_access_key_id: AWS_ACCESS_KEY_ID
aws_secret_access_key: AWS_SECRET_ACCESS_KEY
aws_region_name: us-west-2
import openai
from parea import Parea, trace
p = Parea(api_key="PAREA_API_KEY")
client = openai.OpenAI(api_key="litellm", base_url="<LiteLLM_URL, e.g. http://0.0.0.0:26264>")
p.wrap_openai_client(client)
def llm_call(model: str):
return client.chat.completions.create(model=model, messages=[
{"role": "user", "content": "this is a test request, write a short poem"}
])
@trace
def main():
# request sent to model set on litellm proxy using config.yaml, `litellm --config config.yaml`
response = llm_call(model="claude-3-haiku-20240307")
response2 = llm_call(model="gpt-4o")
response3 = llm_call(model="azure_gpt-3.5-turbo")
response4 = llm_call(model="anthropic.claude-3-haiku-20240307-v1:0")
return {"claude": response, "gpt": response2, "azure": response3, "bedrock": response4}
if __name__ == "__main__":
print(main())
import OpenAI from 'openai';
import { Parea, trace, patchOpenAI } from 'parea-ai';
const openai = new OpenAI({apiKey: 'litellm', baseURL: '<LiteLLM_URL>'});
const p = new Parea(<PAREA_API_KEY>);
patchOpenAI(openai);
async function callOpenAI(model: string) {
return openai.chat.completions.create({
model, messages: [
{ role: 'user', content: 'this is a test request, write a short poem' }
],
});
}
const main = trace( 'main', async () => {
const response2 = await callOpenAI('gpt-4o');
const response3 = await callOpenAI('azure_gpt-3.5-turbo');
return { 'gpt': response2, 'azure': response3 };
},
);
main().then((result) => console.log(result));
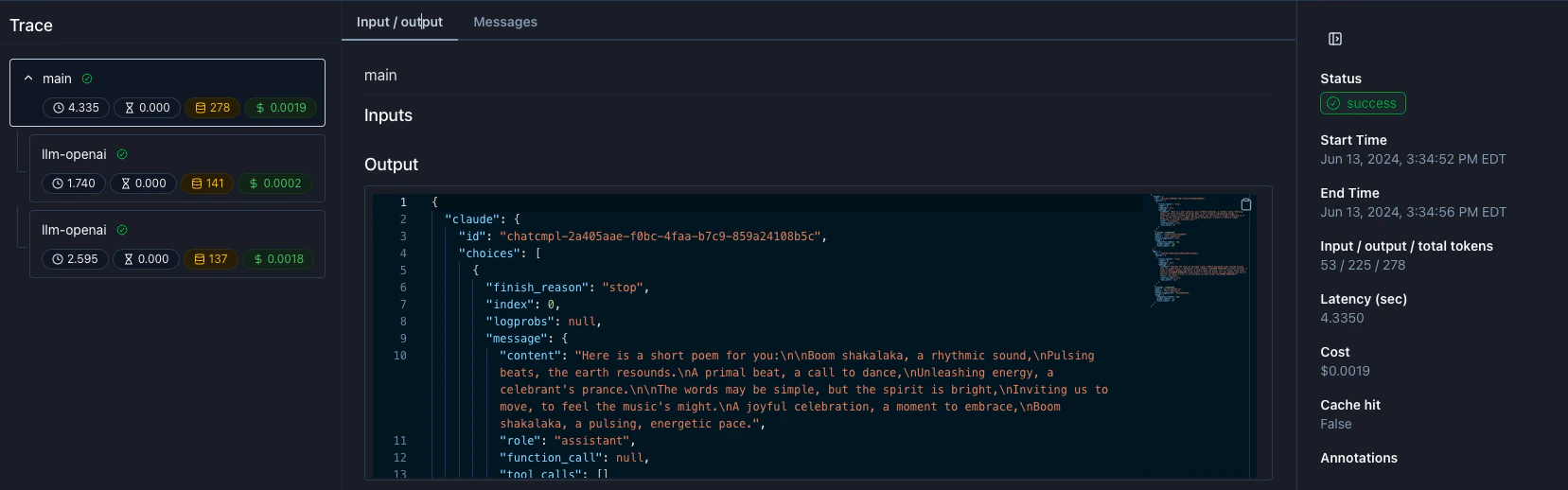
Visualizing your traces
In your Parea logs dashboard, you can visualize your traces and see the detailed steps the LLM took across the various models.